Systém syntézy reči pre slovenský jazyk
Predstavujeme|
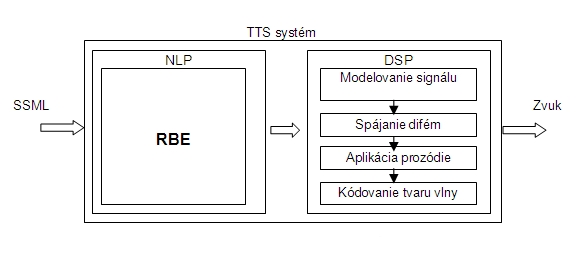
Nasledujúci článok je určený tým našim čitateľom, ktorí sa zaujímajú o možnosti využitia prirodzeného jazyka v počítačových aplikáciách. Systém je možné implementovať do aplikácií, ktoré obsahujú digitalizované knižničné dáta, predovšetkým pre podporu nevidiacich. Úvod V priebehu vývoja systému text-to-speech pre slovenský jazyk (TTS) bola zvolená architektúra založená na štandarde SSML (Speech Synthesis Markup Language) [2]. SSML bol použitý ako základná myšlienka v novom koncepte, pretože špecifikácia poskytuje štandardizovaný spôsob kontroly vlastnosti reči medzi rôznymi platformami syntézy reči. Tento TTS systém sa vyvíja na Katedre informačných sietí (KIS) Žilinskej univerzity a aplikuje systém RBE (rule based engines). Už nejaký čas sú známe metódy, ktoré aplikujú systém RBE. Používajú sa v rozličných vedeckých a komerčných odboroch. Takisto v spracovaní prirodzeného jazyka boli ohlásené alebo publikované určité postupy. Spracovanie prirodzeného jazyka predstavuje dôležitú časť syntézy reči. Na zvládnutie týchto prepisovacích problémov bol vyvinutý systém založený na RBE, ktorý transformuje všeobecný alfanumerický text v SSML formáte do grafém a následne do fonetického prepisu, ktorý môže byť priamo použitý v DSP (digital signal processing) časti systému text-to-speech. Dôvod použitia RBE v TTS bola jeho schopnosť manipulovať so SSML požadovaným spôsobom. Spracovanie textu slovenského jazyka je v systéme rozdelené do oddelených modulov. Každý modul má špeciálne podmienky nazývané pre- a postconditions. Preconditions sú pravidlá, ktoré určujú spustenie modulu a postconditions určujú výsledný efekt spusteného modulu. Špecifické vlastnosti (moduly sú samostatné a majú pre- a postconditions) prinášajú modularitu, flexibilitu a podobnosť. Moduly môžu byť vyvíjané samostatne a môžu riešiť iba špecifické problémy jazyka. TTS SyStém Opisovaný TTS je založený na spojovaní difém1 (elementárnych zvukových jednotiek). Je postavený na SSML štruktúre, ktorá bola použitá pre formát vstupného textu ako jeho stabilný základ. Systém používa syntézu difém, metódu zreťazovacej syntézy, ktorá používa difémy ako základné jednotky zreťazovania. Systém používa jadro syntézy, ktoré bolo vyvinuté na KIS a databázu difém pre slovenský jazyk, ktorá bola tiež vytvorená pre potrebu syntézy. Jadro systému bolo vytvorené kvôli možnostiam lepšej kontroly syntézy a použitia rôznych prístupov počas fázy spájania difém a aplikácie prozódie. Pre požiadavky systému boli vyvinuté nástroje na analýzu a vytváranie difém [3]. Bloková architektúra systému pozostáva z dvoch hlavných častí (obr. 1):
Obr. 1 Architektúra TTS
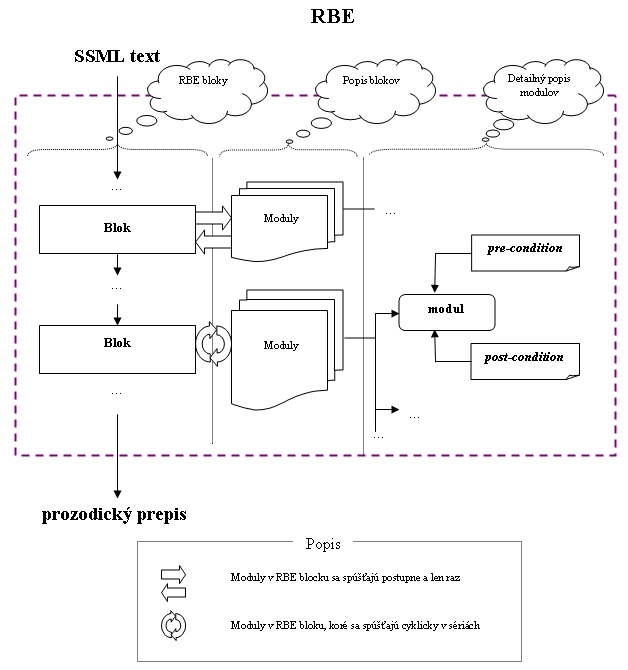
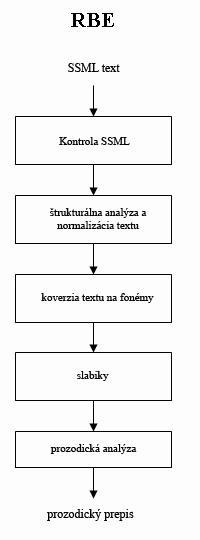
– Natural Language Processing (spracovanie prirodzeného jazyka); je zodpovedný za transformáciu všeobecného vstupného textu v SSML, ktorý je subjektom pre fonetickú transkripciu. Takisto konvertuje čísla, skratky, dátumy atď. do fonetického textu. Princíp spracovania textu je založený na RBE. DSP – Digital Signal Processing (spracovanie digitálneho signálu); je zodpovedný za vytvorenie zvukových dát z fonetického textu. NLP aktívne pracuje nad SSML štruktúrou a mení ju, a DSP pasívne používa informácie poskytnuté NLP. RBE pre spracovanie textu Hlavná funkcia RBE je postupná transkripcia textu do fonetického prepisu. Abstraktná štruktúra RBE:
Obr. 2 Abstraktná štruktúra RBE
RBE pozostáva z nezávislých častí nazývaných “blok”, ako to vidieť na obr. 3. RBE je formované do blokov: Overovanie SSML, analýza štruktúry a normalizácia textu, konverzia textu na fonémy, sylabická a prozodická analýza. Každý blok má špecifické funkcie:
Blok je rozdelený do menších častí nazývaných “moduly ”z dôvodu spustenia jeho úloh. Blok pozostáva z jedného alebo viacerých samostatných modulov. Závisí od požiadavky, ktorý blok sa musí spustiť. Blok určuje, akým spôsobom sa moduly spustia. Moduly môžu fungovať dvomi spôsobmi:
Tieto spôsoby sa nazývajú aj explicitná spúšťacia logika, keď je poradie striktne definované, a implicitná spúšťacia logika, keď sú moduly spúšťané v cykloch. Keď blok ukončil svoju činnosť, je zabezpečené, že blok, napr. konverzia textu na fonémy, je aplikovaný na celý výstup. Pri cyklickom behu modulu sa cyklus znova spustí, pokiaľ niektorý modul nezmení vstup. Spôsob, ako rozhodnúť, či modul spustiť a ako jeho výstup vyzerá, je definovaný podmienkami (každý modul má špecifický “contract”). Podmienky sú precondition a postcondition:
Experimentálne bol vyvinutý abstraktný jazyk, ktorý umožňuje písať pre/postconditions. Dodnes nie je súčasťou implementácie, ale používa sa ako formálny jazyk. Je založený na “first order predicate” logike; obsahuje množinu predikátov, modifikátorov, relačných operátorov, kvantifikátorov a logických funkcií. Moduly Nasledujúca sekcia opisuje niekoľko modulov pre demonštráciu ich atomicity a granularity. Moduly formujú množinu atomických sekcií spúšťaných nad štruktúrou. Tento prístup zjednodušuje pridávanie alebo zlepšovanie existujúcich modulov. Tieto moduly sú:
Účelom tohto modulu je rozdelenie slov do slabík podľa ich výslovnosti. Pred štartom modulu je každé slovo, ktoré má byť rozdelené na slabiky, napísané vo forme fonetického prepisu. Fonetický prepis je písaný v abecede IPA (International Phonetic Alphabet). IPA bola použitá pre jej schopnosť poskytnúť štandardný, presný a špecifický spôsob, ako reprezentovať zvuky akéhokoľvek hovorového jazyka [4].
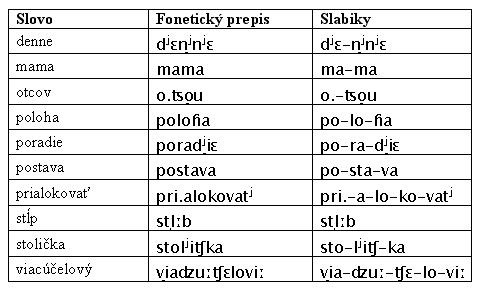
Rozdelenie slova na slabiky (v slovenskom jazyku) je urobené experimentálne podľa kombinácie rozdelenia podľa výslovnosti a automatického delenia, ako to znázorňuje tab. 2. Metóda je nasledujúca:
Rozdelenie na slabiky má nejaké výnimky:
Takisto niektoré exotické a cudzie slová sú dobrým príkladom; napr. prialokovať. Fonetický prepis je pri.alokovatj. Dvojhláska ia sa správa ako dve samohlásky. To znamená, že slovo nie je rozdelené pri.a-lo-ko-vatj, ale pri.-a-lo-ko-vatj.
Tab. 2. Príklady slabík
Tento modul je zodpovedný za aplikovanie pravidiel spodobovania, výber medzi viacerými možnosťami výslovnosti a nakoniec za spájanie slov.
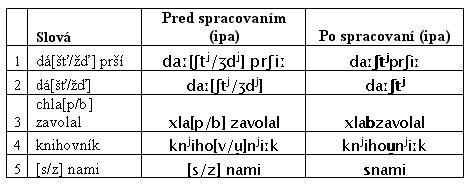
V skutočnosti nie sú vytvárané žiadne nové elementy. V tomto procese je vybraná jedna možnosť výslovnosti slova a druhá možnosť je odstránená aj s riadiacimi znakmi; napr. dá[šť/žď] – dážď. Pri fonetickom prepise vyzerá implementácia ako Pri procese spodobovania platia tieto pravidlá: Ak je nasledujúca hláska neznelá alebo nasleduje koniec vety, je vybraná neznelá hláska. (tabuľka 3: 1. riadok). Inak je spodobená na znelú hlásku (tabuľka 3: 3. riadok). Ak sú možnosti na výber ekvivalentné, spodobovanie nenastane, ale výberová funkcia rozhodne o jednej z možností (tabuľka 3: 4. riadok). Pre prípad výnimky v spodobovaní je definovaná tabuľka s výnimkami (napr. “s nami”). Ak sa spracovávaný výraz nachádza v tabuľke, pravidlá spodobovania sa neuplatňujú, ale je použitá výnimka (tabuľka 3: 5. riadok). Ku spodobovaniu tiež nedochádza medzi vetami, a v prípade, keď nastane vloženie medzier alebo zvukových súborov. V poslednom kroku je overované spojenie slov. Ak sa vyskytlo spodobenie na konci slova, nastane spojenie s nasledujúcim.
Modul Xphone vkladá element xphone do elementu syllable. Rozdeľuje slabiky na difémy (xfémy 2).
Proces vytvárania elementov xphone: Modul spracováva elementy syllable a zisťuje či sú k dispozícii trifémy. Ak nie sú, použijú sa difémy. Diféma pozostáva z dvoch elementov ph, ktoré sú nastavené týmto spôsobom: Ak sa diféma nachádza:
Posledný ph element a prvý ph element za sebou nesledujúcich xfém sú ekvivalentné. Trifémy sa vytvárajú podobným spôsobom.
Obr. 4 Príklad spracovania samostatného slova ”na” Rozdeľovanie na elementy xphone je posledným krokom, ktorý je aplikovaný v záujme zmeny textovej štruktúry. Konečná štruktúra je pripravená na vstup do modulu DSP (digitálneho spracovania zvuku), ktorý slúži na generovanie zvuku. Záver V článku bol prestavený koncept TTS systému, ktorý je založený na SSML štruktúre. Spracovania prirodzeného jazyka v systéme je založené na RBE kvôli jeho schopnosti manipulovať s SSML. Metóda RBE poskytuje silný nástroj na vývoj robustných a flexibilných systémov. Vývojový proces pridávania nových modulov na spracovanie textu a manipulácia s existujúcimi modulmi neovplyvňuje iné moduly ani samotný rečový systém. Článok ďalej prezentuje niektoré špecifické moduly RBE použité v spracovaní textu pre slovenský jazyk. Snažili sme sa vybrať moduly, ktoré ukazujú špecifické problémy slovenského jazyka.
Literatúra
1Susediaci pár foném. Označuje prechod medzi dvomi hláskami. 2Xféma označuje možnosť, že bude použitých viac ako 2 fonémy (ako pri diféme) kvôli realistickejšiemu výstupu zvuku. |