|
Rozhrania na prieskum: FRBR a identifikátory
Úvod
Európska skupina pre automatizáciu knižníc (European
Libraries Automation Group – ELAG), založená roku 1979 [1], je otvorené fórum
expertov, ktoré združuje takmer 500 odborníkov z 27 krajín Európy a ostatného sveta
(USA, India, Japonsko…). Komunita ELAG sa raz ročne stretáva na konferencii so
zameraním na problematiku technológií knižničného a informačného manažmentu,
ktorá pozostáva z troch častí: plenárnych prezentácií s diskusiou na rok vopred
zvolenú tému, expertných pracovných seminárov (workshops) o súvisiacich
odborných otázkach a z posterových prezentácií (lightning talks) najnovších
myšlienok a riešení. Konferencia je príležitosťou na podrobnú diskusiu o
súčasných a nastupujúcich problémoch, na prezentáciu úspešných projektov a najmä
na výmenu názorov, nápadov a praktických skúseností. 33. výročná
konferencia ELAG´2010 sa konala pod záštitou Fínskej národnej knižnice v dňoch 9.
– 11. júna v Helsinkách v priestoroch helsinskej univerzity. Zúčastnilo sa jej 190
expertov z 18 krajín. Súčasťou konferencie bola výstava sponzorujúcich dodávateľov
informačných technológií. Nosná téma tohoročnej konferencie znela „V ústrety
očakávaniam nových používateľov“ (Meeting new user expectations) [1, 2, 3].
Pracovné semináre ELAG 2010
Tradičnou súčasťou konferencie sú pracovné semináre expertov,
tzv. workshopy, ktoré sú organicky začlenené do programu a prelínajú sa s
plenárnymi prezentáciami. Toho roku prebiehalo sedem paralelných workshopov.
- Pracovný seminár a kurz Solr (Solr workshop) moderovali Age
Jan Kuperus a Joost van Ingen (Wageningen UR Library, NL). Solr je open source
vyhľadávací softvér (enterprise search server) založený na indexovacích nástrojoch
Lucene. Poskytuje plnotextové prehľadávanie, fazetový prieskum, distribuovanú
replikáciu indexov, integráciu databáz a ďalšie možnosti na skvalitnenie webového
prieskumu a administrácie. Solr je veľmi dobre škálovateľný, využíva sa na
navigáciu a vyhľadávanie v najväčších internetových sídlach na svete.
Účastníci seminára sa oboznámili s architektúrou a funkciami systému, ktoré si
prakticky overili na vlastných počítačoch a údajoch.
- Pracovný seminár a kurz Webové služby (Web Services
workshop) moderovala Karen Coombs (OCLC). Webové služby sa využívajú na zdokonalenie
knižničných služieb a používateľských rozhraní knižničných systémov. Ich
rozvoj je reakciou na exponenciálny nárast knižničných údajov (bibliografických,
autoritných, plnotextových…). Príkladom sú webové služby OCLC: xISSN, xISBN,
WorldCat Search API, WorldCat Identities, QuestionPoint, ktoré rozširujú praktické
možnosti používateľov. Čoraz viac webových služieb podporuje prepájanie
údajov (data linking): OpenURL resolver, LCSH [4], Dewey.info, OpenLibrary, VIAF
[5]. Účastníci kurzu sa oboznámili s prieskumovými protokolmi na prácu s rôznymi
formátmi údajov (XML, JSON, HTML), skriptovacími nástrojmi na ich manipuláciu v
prostredí klient – server a s celkovými možnosťami využitia webových služieb v
knižničných aplikáciách.
- Pracovný seminár Rozhrania na prieskum 1: Čo je treba a čo je
k dispozícii (Discovery interfaces 1: What’s needed and what’s available?)
moderoval Till Kinstler (Verbundzentrale des GBV). Rozhrania na prieskum poskytujú
jednoduchší a jednotný prístup k rôznym knižničným prameňom. V súčasnosti sa
využíva množstvo komerčných programových systémov, ako sú Blacklight,
Aquabrowser a Summon (Serial Solutions), VuFind, Primo (Ex Libris),
Touchpoint a Worldcat (OCLC), eXtensible Catalog, ale aj proprietárnych riešení
napríklad v projektoch Beluga alebo Summa. Navzájom sa odlišujú v technickom
riešení, funkcionalite, architektúre alebo v obchodnom modeli vrátane
najrôznejších obmedzení. Účastníci seminára sa oboznámili s charakteristikami
týchto systémov a konfrontovali ponúkané možnosti s požiadavkami knižníc a
používateľov [15].
- Pracovný seminár Rozhrania na prieskum 2: FRBR a identifikátory
(Discovery interfaces 2: FRBR and identifiers) moderovala Janifer Gatenby (OCLC).
Podrobnejšie o tomto seminári budeme písať v samostatnej časti tohto príspevku.
- Pracovný seminár Poznajme našich používateľov (Knowing our
users) moderovala Marit Brodshaug (BIBSYS, NO). Prezentovala tri prípadové štúdie
z nórskych knižníc zamerané na metodiku a prax spoznávania používateľov
(interných a externých) a propagáciu knižníc a ich služieb. Medicínska knižnica
Innlandet Hospital Trust si predsavzala byť podstatnou službou pre inštitúciu a
rozvinula zodpovedajúcu komunikačnú a marketingovú stratégiu voči svojej vrchnosti a
verejnosti. Oxford University College zapojila s cieľom zlepšiť plnenie očakávaní
používateľov do procesov marketingu knižnice a jej služieb študentov. Ukázalo sa
napríklad, že knižnice používajú často úplne inú terminológiu ako ich
používatelia. Norwegian University of Science and Technology sa zamerala na zlepšenie
prvého dojmu používateľov, pričom sa použili videoprezentácie a publikovanie
skúseností študentov pri využívaní knižničných služieb. Účastníci seminára
diskutovali o možnostiach analýzy poskytovaných služieb z hľadiska potrieb
používateľov a scenároch na maximalizáciu využitia knižničných prameňov.
- Pracovný seminár Pramene údajov (Data wells) moderoval
Steen Manniche (DBC, DK). Pojem Data wells má pôvod v projekte systémovej
infraštruktúry a zdieľaných údajov kooperačného systému dánskych verejných
knižníc Ting [6]. Predstavuje infraštruktúru na vkladanie (ingest), normalizáciu a
integrovaný prístup k mnohonásobným prameňom údajov. Knižničné služby sa podľa
tohto konceptu rozvíjajú na konsolidovanej báze údajov na rozdiel od aktívnej
integrácie pri metaprieskume. V knižniciach narastá potreba správy a
sprístupňovania digitálnych údajov. Jedným z nástrojov na to sú úložiská
digitálnych objektov. Účastníci seminára skúmali možnosti využitia existujúcich
objektovo orientovaných systémov, ako je napríklad Fedora Commons [7] na budovanie prameňov
údajov, v ktorých sa aplikujú bibliografické nástroje s cieľom prepojiť
prehľadne štruktúrovaný a ľahko prístupný bibliografický aparát s obsahom na
internete [8].
- Pracovný seminár E-pamäť (E-memory) moderoval Ramon Ross
(CBUC, ES). Pojmom e-pamäť sa rozumie digitalizácia miestnych prameňov, ku ktorým má
každý prístup vrátane možnosti dopĺňať túto „spoločenskú pamäť“. Narastá
množstvo lokálnych projektov digitalizácie a tým aj potreba stabilnej infraštruktúry
na dlhodobé uchovanie digitálneho obsahu, jeho zdieľanie, ľahké využívanie vrátane
tvorby pridanej hodnoty. Zachovanie písomnej a tlačenej pamäti patrí k
základným úlohám knižnice. Realizácia môže byť rôzna: vyvinúť vlastné služby
alebo použiť jestvujúce, centralizovať všetky pramene v jednom sídle alebo prepojiť
viaceré sídla a projekty. Cieľom seminára bola výmena skúseností a diskusia o
rozdielnych prístupoch k implementácii a správe e-pamäti v knižniciach. Hovorilo sa o
softvérových nástrojoch, výbere materiálov, zapojení používateľov, uchovávaní,
koordinácii, úspešných projektoch [9-13] a ďalších aktuálnych otázkach vrátane
odporúčaní pre začiatočníkov a nových zámerov pokročilých.
- Účastníci konferencie sa rozdelili podľa záujmu do siedmich
pracovných skupín, ktoré rokovali súbežne v štyroch programových blokoch. Správy
zo seminárov sa prezentovali ich moderátori vo vyhradenom čase v závere konferencie
[3].
Pracovný seminár FRBR a identifikátory
Ako sme už spomínali, pracovný seminár Rozhrania na prieskum
2: FRBR a identifikátory (Discovery interfaces 2: FRBR and identifiers)
pripravila, viedla a vyhodnotila Janifer Gatenby (OCLC). Obsahom seminára bola rozprava o
identifikátoroch informačných prameňov, autoroch a ďalších súvisiacich entitách
vo vzťahu k modelu FRBR, ako aj hľadanie odpovede na otázku, akú úlohu majú mať
knižnice v oblasti identifikácie prameňov a šírenia, údržby a používania
identifikátorov a identifikačných systémov. Cieľom bolo zmapovať a analyzovať
identifikačné procesy (identifier landscape), pokrytie identifikačných potrieb z
hľadiska kompletnosti a typovej rozmanitosti, pokúsiť sa o ich priemet do jednotlivých
vrstiev FRBR a preskúmať význam identifikátorov pri vyhľadávaní a prepájaní
údajov (discovery and linking data).
V súčasnosti sa využíva a rozvíja množstvo rôznych
štandardizovaných a proprietárnych identifikátorov a priebežne vznikajú nové
identifikačné schémy. Na úrovni diela (FRBR work) je to napríklad ISTC (International
Standard Text Code), OWI (OCLC Work Identifier), ISWC (International Standard Work Code),
ISAN (International Standard Audiovisual Number). Na úrovni stvárnenia (FRBR expression)
sú to ISSN (International Standard Serial Number), ISRC (International Standard
Record Code) a na úrovni prejavu (FRBR manifestation) ISBN (International Standard Book
Number), ISMN (International Standard Music Number), DOI (Digital Object Identifier), ARK
(Archival Resource Key), LCN (Library of Congress Number), OCN (OCLC Control Number). V
oblasti identifikácie tvorcov je známy štandard ISNI (Interna-tional Standard Name
Iden-tifier) alebo ORCID (Open Research Contributor Identifier) a ďalšie. Zložitosť
identifikácie nespočíva pritom iba v množ-stve rôznych, prevažne štandardizovaných
schém, ale aj v metodike ich aplikácie. Ako príklad možno uviesť komplexné
používanie ISSN: na úrovni diela sa aplikuje ISSN-L, ktoré je zhodné s ISSN svojho
prvého stvárnenia – vydania titulu, na úrovni stvárnenia sa prideľuje separátne
ISSN pre printovú a online verziu, na úrovni manifestácie sa používa zhodné ISSN pre
originál a digitalizovanú verziu.
Východiskom na rozpravu bola základná schéma modelu FRBR so
štyrmi samostatnými vrstvami pre dielo, stvárnenie, manifestáciu a jednotku (work,
expression, manifestation, item). Z hľadiska posudzovania globálnej (sieťovej)
aplikácie identifikátorov sa pozornosť sústredila na tri vrchné vrstvy modelu FRBR
(obr. 1).
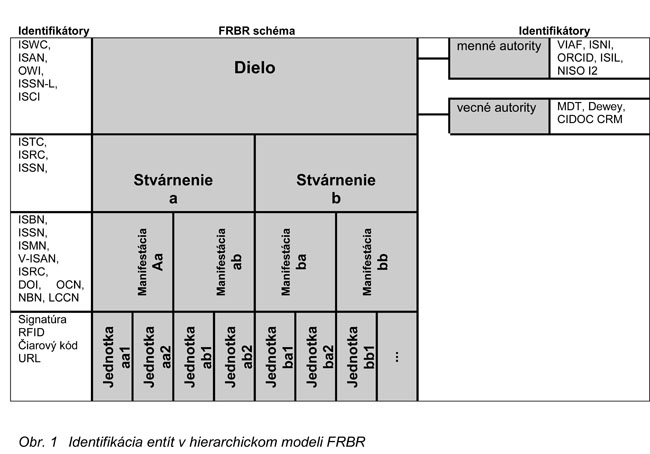
Pracovná skupina sa postupne venovala problémom v troch
tematických okruhoch: Existujúce identifikátory a iniciatívy, Identifikátory ako
nástroj na vyhľadávanie/prepájanie a Identifikátory a prepojené údaje.
V rámci témy Existujúce identifikátory a iniciatívy sa
diskutovalo o týchto otázkach:
– Do akej miery vyhovujú existujúce identifikátory
modelu FRBR?
– Existujú medzery v pokrytí jednotlivých vrstiev
FRBR pre klasické a elektronické pramene? V akom rozsahu sú existujúce identifikátory
reprezentované v knižničných katalógoch?
– V akom rozsahu sú existujúce identifikátory
rozšírené mimo knižničných systémov?
– Akú úlohy by mali knižnice mať pri rozvoji a
údržbe týchto identifikátorov?
Identifikátory sú v porovnaní s metaúdajmi lepším nástrojom
na kreovanie a vyhľadávanie asociácií. Na jednoznačnú identifikáciu diela
metaúdajmi treba použiť komplexné formáty s množstvom elementárnych prvkov, pričom
ich zápis nemusí byť vždy totožný. Dobrý identifikačný systém zaručuje nielen
koordináciu bibliografických záznamov, ale aj prepojiteľnosť k dielu, stvárneniu a
manifestácii. Má však aj iné funkcie podľa spôsobu a účelu využitia. Požiadavky
vydavateľského trhu, správy autorských práv a knižničných systémov sa nie vždy
prekrývajú, čo viedlo v minulosti a vedie aj v súčasnosti k vzniku viacerých
kvázikonkurenčných identifikačných systémov a spôsobov. Každej vrstve
modelu FRBR možno dnes priradiť niekoľko typov identifikátorov, ktoré aj keď sa
čiastočne prekrývajú, navzájom sa nevylučujú a treba ich používať podľa potreby
súbežne. Vzhľadom na rozsah priebežného a retrospektívneho použitia neexistuje
zatiaľ univerzálny globálny identifikátor výhradne použiteľný pre danú vrstvu.
Záleží to najmä na rozšírení a miere využívania v katalógoch, resp. súborných
katalógoch, ale aj na ich veľkosti. V katalógu Worldcat obsahuje asi len 30 % záznamov
niektorý z medzinárodných identifikátorov (70 % monografií má ISBN). OCLC zaviedlo v
katalógu Worldcat niekoľko typov identifikátorov s globálnym potenciálom: OCLC
work identifier (OWI), OCLC record identifier (OCN). Kongresová knižnica používa
číslo záznamu LCCN, národné knižnice inklinujú k číslu národnej bibliografie
NBN. Problémom môže byť aj rôzna interpretácia metodiky identifikácie, ktorá je
niekedy vystavená tlaku vydavateľov a kníhkupcov, ktorí potrebujú identifikátory na
obchodné účely. Aktuálna je snaha presadiť prideľovanie jedného ISBN
manifestáciám diela na rôznych médiách, ktorá je v protiklade s názorom, že aj
každý rôzny formát elektronickej publikácie (.pdf, .html, .pdb…) publikovaný a
samostatne prístupný má mať vlastné ISBN. V medzinárodnej sieti ISSN sa hľadá
riešenie na identifikáciu digitalizovaných kópií, ktoré nemusia byť identické s
elektronickými verziami odpovedajúcich titulov (diel). Účastníci seminára
konštatovali, že identifikácia riadená a dôsledne uplatňovaná knižnicami je
zárukou zachovania kvality bibliografickej registrácie a následného efektívneho
vyhľadávania a prepájania informačných prameňov.
V tematickom bloku Identifikátory ako nástroj na vyhľadávanie
sa diskutovalo o rôznych možnostiach prepájania záznamov a entít v modeli FRBR
(dielo/dielo, manifestácia/manifestácia, autor/dielo…), ako aj o iných asociáciách
explicitne nepokrytých FRBR, ako sú originály a reprodukcie, rôzne jazykové opisy a
pod. V rámci diskusie sa riešili aj otázky:
– Ako sú tieto asociácie reprezentované v
knižničných katalógoch?
– V akom rozsahu sú tieto asociácie reprezentované vo
veľkých webových sídlach (Amazon…)?
– Akú úlohu majú identifikátory pri rozvoji a
údržbe týchto liniek?
Identifikácia na úrovni diela nie je tak jednoduchá ako na
úrovni manifestácie. Samotné dielo môže byť vydané vo viacerých krajinách v
rôznom časovom rozpätí. Priradenie by malo byť retrospektívne. Identifikácia diela
je použiteľná na správu autorských práv a pri všeobecnom vyhľadávaní, menší
význam má pre vydavateľov. V niektorých prípadoch sa zavádzajú tzv.
združovacie identifikátory (collocating identifiers), ktoré prepájajú rôzne
stvárnenia a manifestácie diela, ako je ISSN-L alebo Global Library Manifestation
Identifier – GLIMIR. Nový rozmer v tomto ohľade predstavuje medzinárodný
identifikátor International Standard Collection Identifier – ISCI [14] na kolektívnu
správu virtuálnych zbierok. Dôležitou súčasťou modelu FRBR je prepájanie diel a
tvorcov (creator), resp. držiteľov autorských práv. Vývoj smeruje k budovaniu a
harmonizácii rozsiahlych súborov autorít vrátane zodpovedajúcich identifikačných
systémov. OCLC združila a porovnala v rámci projektu Virtual Autority File – VIAF
súbory viac než 12 národných systémov, čo predstavuje okolo 14 mil. záznamov.
Ďalšími systémami na mennú identifikáciu sú napríklad International Standard Name
Identifier – ISNI, Open Researcher and Contributor ID – ORCID, Interested Party
Identifier – IPI a pre korporácie NISO Institutional Identifier – NISO I2.
V tematickom bloku Identifikátory a prepojené údaje sa
analyzoval význam zdieľaných identifikátorov pre sémantický web. Termínom
prepojené údaje (linked data) sa označujú jednotne identifikované (URI) súbory
navzájom previazaných elementárnych údajových entít (RDF). Prepojené údaje sú
nositeľom informácie o vzájomnej súvislosti – vyjadrujú vnútorné prepojenia,
nevytvárajú ich. Vnútorné väzby trojíc (subject-predicate-object) treba
najskôr vytvoriť, na čo možno optimálne využiť univerzálne identifikačné
schémy. Identifikátory napomáhajú využitie prepojených údajov pri informačnom
prieskume prostredníctvom vyhľadávacích protokolov a webových služieb. Aktuálnou
úlohou knižníc by malo byť čo najširšie dôsledné zavedenie štandardných
identifikátorov do katalógov, ako aj ich včlenenie do elektronických
publikácií, webových stránok a digitálnych knižníc.
Glosár
| API |
(Application Programming Interface)
Programovateľné rozhranie, ktoré sa využíva na prístup k elektronickým službám
a umožňuje spoluprácu rôznych aplikácií, programových
a operačných systémov. |
| ARK |
(Archival Resource Key)
URL na trvalý, dlhodobý prístup k informačným objektom. Používa sa na
identifikáciu rôznych typov digitálnych objektov (dokumenty, bázy údajov,
obrazy, softvér, webové stránky), fyzických objektov (knihy, artefakty…), ako
aj nehmotných objektov (choroby, chemické zlúčeniny, slovníkové termíny,
prestavenia…). |
| DOI |
(Digital Object Identifier)
Identifikátor (znakový reťazec) previazaný s metaúdajmi, určený na jednoznačnú
trvalú identifikáciu elektronických dokumentov a objektov, používaný na
kontrolovaný prístup (komerčný a nekomerčný). Metaúdaje obsahujú priebežne
aktualizovanú adresu uloženia dokumentu (URL). |
| FRBR |
(Functional Requirements for Bibliographic Records)
Inovatívny entitno-relačný model novej koncepcie bibliografickej kontroly, ktorý
preferuje používateľské hľadisko pri prieskume a prístupe do online knižničných
katalógov a bibliografických databáz. |
| GLIMIR |
(Global Library Manifestation Identifier)
Projekt iniciovaný OCLC, pôvodne implementovaný v katalógu WorldCat, na prepojenie
všetkých záznamov metaúdajov toho istého prameňa alebo publikácie. |
| IPI |
(Interested Party Information)
Globálny systém na identifikáciu autorských práv v oblasti umeleckej tvorby
(hudba, literatura, umenie…), zohľadňujúci rôzne roly (skladateľ, režisér, herec,
autor…) a práva (výkon, reprodukcia, vysielanie…) a obsahujúci
informácie o zainteresovaných stranách – osobách a inštitúciách. |
| ISAN |
(International Standard Audiovisual Number)
Dobrovoľný systém na identifikáciu a registráciu metaúdajov audiovizuálnych diel
a ich verzií (filmy, TV programy, reklama, športové prenosy, dokumentárny film…).
ISO 15706-1 a 15706-2: 2007. |
| ISCI |
(International Standard Collection Identifier)
Medzinárodný systém na jednoznačnú identifikáciu zbierok fondov a ich častí
(knižnice, múzá a archívy). ISO DIS 207730. |
| ISRC |
(International Standard Recording Code)
Medzinárodný identifikačný systém pre zvukové záznamy a hudobné videozáznamy.
Jednoznačný a trvalý identifikátor možno zakódovať do nosiča na účely
automatickej registrácie a správy autorských odvodov. |
| ISSN-L |
(linking ISSN)
Umožňuje kolokáciu alebo prepojenie vydaní prameňa na pokračovanie na rôznych
médiách. STN ISO 3297: 2008. |
| ISTC |
(International Standard Text Code)
Číslovací systém určený na jednoznačnú identifikáciu textových diel. ISO
21047. |
| JSON |
(JavaScript Object Notation)
Jednoduchý formát na výmenu údajov naprogramovaný ako Javascript. |
| LCCN |
(Library of Congress Control Number)
Priebežný systém číslovania katalógových záznamov dokumentov v zbierkach
(katalógu) Kongresovej knižnice USA. |
| NISOI2 |
(Institutional Identifier)
Pripravovaný symbol/kód na jednoznačnú identifikáciu inštitúcií, ktorý by mal
opisovať vzťahy medzi entitami vnútri inštitúcií s cieľom navzájom rozlíšiť
jednotlivé inštitúcie. |
| OCLC |
(Online Computer Library Center)
Nezisková servisná a výskumná organizácia zameraná na podporu knižničných
činností (lokalizácia, akvizícia, katalogizácia, cirkulácia…). Je správcom
katalógu WorldCat vrátane autoritných a pomocných báz a sprievodných
služieb. |
| OCN |
(OCLC Control Number)
Jedinečné, sekvenčne priradené číslo katalógového záznamu v katalógu
WorldCat. Zapisuje sa v okamihu vytvorenia záznamu. OCN sa využívajú pri realizácii
elektronických služieb OCLC (WorldCat Local, WorldCat Navigator…). |
| ORCID |
(Open Research and Contributor Identifier)
Navrhovaný univerzálny alfanumerický kód na trvalú a jednoznačnú identifikáciu
vedeckých a akademických autorov. Register má obsahovať online individuálne profily s
údajmi o publikáciách, kontaktoch, projektoch a pod. |
| OWI |
(OCLC Work Identifier)
Identifikátor diela v katalógu WorldCat, ktorý umožňuje združiť viaceré vydania
publikácií diela (reprinty, preklady, digitalizované kópie…) podľa modelu FRBR. OWI
uľahčuje navigáciu medzi jednotlivými stvárneniami alebo manifestáciami toho istého
diela v katalógu. |
| RDF |
(Resource Description Framework)
Všeobecná špecifikácia modelu metaúdajov a metodika na konceptuálny opis
informácií obsiahnutých vo webových prameňoch. |
| URI |
(Uniform Resource Identifier)
Identifikačná schéma – reťazec znakov na identifikáciu názvu alebo prameňa na
internete. Umožňuje a určuje spôsob narábania s prameňmi v sieti WWW. Schémy URL a
URN sú podmnožinami URI. |
| URL |
(Uniform Resource Locator) je URI odkazujúci na miesto
uloženia dokumentu a mechanizmus prístupu k nemu (globálna adresa informačného
prameňa/objektu na webe). Prvá časť adresy určuje protokol, druhá určuje
doménu, miesto prístupu a názov prameňa. |
| VIAF |
(The Virtual International Authority File)
Medzinárodný projekt viacerých národných knižníc (18) implementovaný a
spravovaný OCLC. Cieľom projektu je zníženie nákladov na katalogizáciu a nárast
využívania súborov knižničných autorít na základe previazaných
a navzájom porovnaných súborov autorít sprístupnených cez web. |
| xISBN |
(OCLC Web service)
Webová služba na poskytnutie údajov, ISBN a sprievodných informácií o
intelektuálnom diele so záznamom v katalógu WorldCat. Po odoslaní ISBN služba vráti
zoznam príbuzných ISBN a vybratých metaúdajov. |
| xISSN |
(OCLC Web service)Webová služba na podporu správy
informácií o seriáloch. Po odoslaní ISSN služby vráti ISSN a informácie o
predchádzajúcom alebo nasledujúcom titule, prípadne iných súvisiacich vydaní. |
Referencie a odkazy
[1] ELAG: http://www.elag.org
[2] ELAG 2010: http://elag2010.nationallibrary.fi/programme/
[3] Androvič, A.: ELAG 2010. V
ústrety očakávaniam nových používateľov. In: Bulletin UKB, roč. 12,
2010, č. 1, s. 36 – 45. ISSN 1210-2016
[4] LOC: http://id.loc.gov/authorities
[5] VIAF: http://viaf.org
[6] DBC: http://oss.dbc.dk/plone/software
[7] Fedora Commons: http://www.fedora-commons.org/
[8] Linked Data: http://linkeddata.org/
[9] Europeana: http://europeana.eu/portal/
[10] Utah Digital Newspapers: http://digitalnewspapers.org/
[11] World Digital Library: http://www.wdl.org/en/
[12] WW2 People’s War: http://www.bbc.co.uk/ww2peopleswar/
[13] Bundesarchiv in Wikimedia: http://commons.wikimedia.org/wiki/Commons:Bundesarchiv
[14] ISO DIS 207730 – International Standard
Collection Identifier
[15] http://sites.google.com/site/urd2comparison/home/comparison
|