http://www.archive.org/index.html – Celosvetový archív internetu
Krok za krokom
Dokonalá orientácia na internet a schopnosť v čo najkratšom čase získať všetky požadované informácie sú snom každého
používateľa internetu. Napriek bohatosti vyhľadávacieho softvéru, ktorý prístup k požadovaným informáciám uľahčuje, chýba nám
nastolenie určitého vnútorného internetového poriadku, ktorý by zjednodušil dosť komplikované prehľadávanie svetového webu,
ako aj okamžité hodnotenie kvality získaných informačných zdrojov, ktorá je až príliš často predmetom polemík.
Žiadané a kvalitné informácie sa stávajú obsahom tematicky zameraných informačných internetových brán. Súčasťou týchto
brán bývajú aj virtuálne knižnice dokumentov. Podoba stránok vystavených na internete však nie je trvalá. Stránky podliehajú
zmenám, úpravám, zrušeniu. Optimálne sprístupnenie dokumentov preto nespočíva v podobe odkazov priamo na ich internetové
zdroje, ale vhodnejšie je zaujímavé materiály umiestniť (skopírovať) na vlastný server, kde môžu byť archivované a
sprístupňované ľubovoľne dlhé obdobie bez ohľadu na “osud” ich pôvodného zdroja.
Na tejto báze pracuje aj Internet archive, ktorý si však kladie za cieľ oveľa viac ako len vytvorenie virtuálnej
knižnice lokálneho či rezortného významu. Jeho cieľom je archivovať celý verejne prístupný obsah svetového internetu tak, aby
bolo možné nájsť aj tie stránky, ktoré boli medzičasom zrušené alebo premiestnené. Projekt realizuje spoločnosť Internet
Archive z amerického San Francisca. V spolupráci s firmou Alexa Internet bola vytvorená vyhľadávacia služba Wayback Machine,
ktorá umožňuje archív prehľadávať. Autori uvádzajú, že v archíve sa v súčasnosti nachádza asi 10 miliárd stránok.
Súčasťou Internet Archive sú aj vyčlenené samostatné tematické zbierky:
- Prezidentské voľby v roku 2000
- Teroristický útok 11. 9. 2001
- Filmy natočené od roku 1903
- Inštitúcie, ktoré publikovali na internete od jeho prvopočiatkov (napr. NASA, Biely Dom, Yahoo…)
Našou snahou bolo vlastnosti archívu dôkladne otestovať a nájsť nielen nesporné pozitíva projektu, ale aj jeho slabé
stránky. Archív je tvorený od roku 1996 a ako hlavné vyhľadávacie kritérium slúži internetová adresa, ktorú možno doplniť
požiadavkou na niektorý zo spracovávaných rokov. Vecné vyhľadávanie, ktoré by sa žiadalo hlavne v prípade, že presné URL
nevieme, nie je v systéme zabudované. Internetovú adresu treba zadať presne, systém pozitívne reagoval len na vynechanie
textu www.
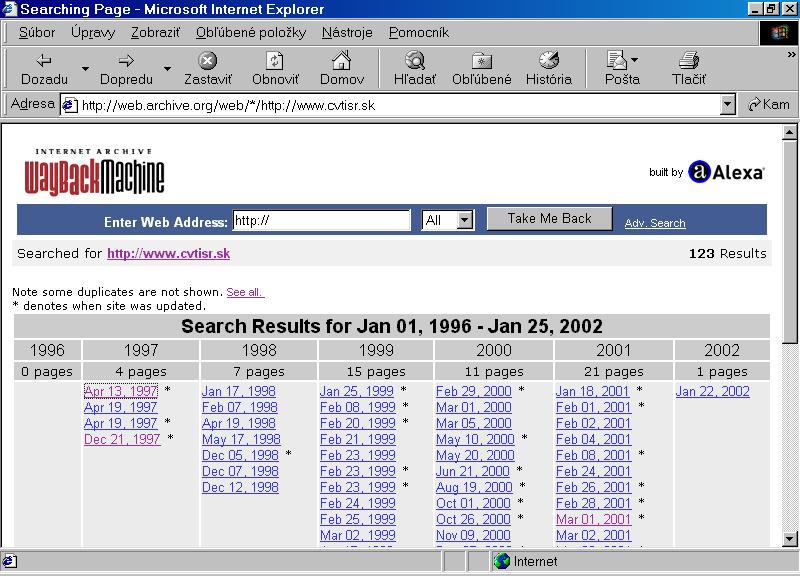
Najčastejšie používaný spôsob, ako otestovať svetovosť archívu, je vyhľadanie niektorej z celosvetového hľadiska
nevýznamnej slovenskej adresy, najlepšie vlastnej (v duchu príslovečnej slovenskej skromnosti…). Tu internetový archív
obstál na jednotku. Našiel adresu Centra vedecko-technických informácií SR pod aktuálnou i starou doménou.
Ďalšou zaujímavou požiadavkou bolo zistiť frekvenciu aktualizácie archívu. Najlepším testovacím materiálom na tento
účel je denná tlač. Archív obsahuje aj URL slovenskej dennej tlače, napríklad SME a Pravda. Pri analýze stránok týchto
denníkov zistíme, že (prakticky) denná aktualizácia je vykonávaná asi od septembra 2001. Od roku 2000 bola vykonávaná
aktualizácia zrejme len niekoľkokrát mesačne a s najväčšou pravdepodobnosťou bez testovania zmien na stránke. Testovanie, či
systém reaguje na to, či na stránke od posledného archivovania nastali nejaké zmeny, sme uskutočnili na adrese zrušeného
denníka Slovenská Republika. Dôkazom je priebežné zobrazovanie stránok až do konca septembra 2001 napriek tomu, že denník bol
v novembri 2000 zrušený a odvtedy sa na jeho URL nachádza jedna a tá istá informácia. V archíve sa teda vyskytujú aj
duplicitné informácie.
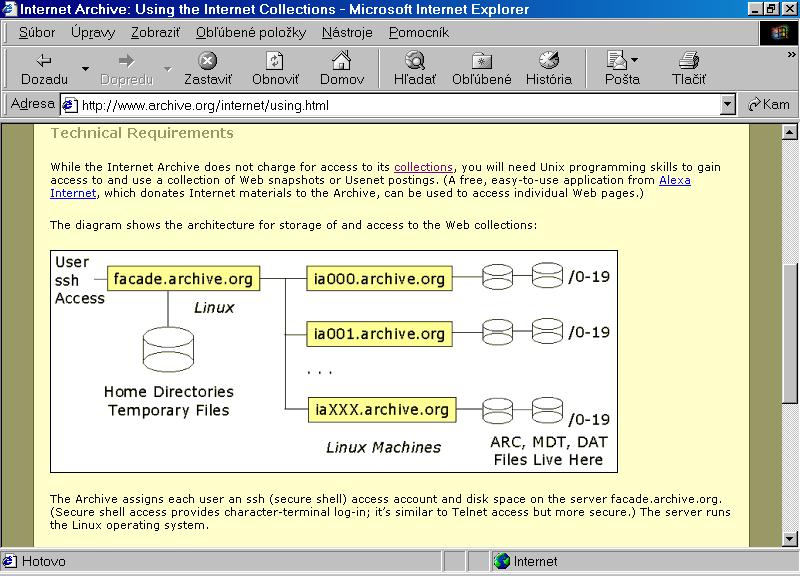
Architektúra Internet Archive
Niektoré stránky nie sú kompletne zrekonštruované, alebo k vyhľadanej linke v archíve chýba zdrojový súbor (hľadaná
stránka). Týka sa to napríklad v súčasnosti už neexistujúcej stránky www.theinfocentre.com, ktorá poslúžila CVTI SR ako zdroj
freeware Websis, na základe ktorého bol vybudovaný náš webový katalóg. Žiaľ, táto stránka sa ani v jednej staršej verzii v
archíve nenachádza kompletná. Nie je tiež možné z archívu zistiť, kam sa na nej uvedené informácie premiestnili. (Treba
poznamenať, že softvér Websis sa skutočne premiestnil a opäť je k dispozícii, čo sme však zistili iným spôsobom než
prehľadávaním internetu.)
Ani vyhľadávač Internet Archive nie je všemocný. Otázka, ako “dostať” svoju dosiaľ nezaradenú stránku do internetu,
alebo naopak, ako stránku z archívu vyradiť, ale aj odpovede na mnohé iné často formulované otázky k jednotlivým zbierkam
možno nájsť v rubrike Frequently asked questions, ktorá existuje ku všetkým tematickým “subbázam”.
Zaželajme tvorcom tohto ambiciózneho projektu nevysychajúci zdroj energie (a štedrých sponzorov), aby sa im podarilo
doviesť ho do maximálne možnej dokonalosti. Nech slúži nielen ako kuriozita, ale aby sa stal základným informačným a
archívnym zdrojom nielen pre radových internetových “surferov”, ale aj pre tvorcov informačných portálov. V priebehu rokov by
projekt budovaný na báze archivácie “historických” dokumentov (zaujímavé by boli nielen virtuálne), mohol ašpirovať aj na
označenie svetového internetového múzea či skanzenu, ktorého potreba vytvorenia bude rásť priamo úmerne k dĺžke existencie
internetu a k rozsahu a hĺbke zmien, ktorými tento fenomén posledného desaťročia od svojich počiatkov prešiel a ešte
prejde.
Celkom na záver uvedieme jeden technický údaj, ktorý nepoteší výhradných obdivovateľov softvérovej platformy Windows.
Projekt Internet Archive využíva niekoľko sto serverov s 512 MB RAM a diskami s kapacitou 300 GB. Servery fungujú pod
operačným systémom Linux…
Literatúra:
http://www.archive.org/index.html
http://www.ikaros.ff.cuni.cz/2001/c12/archive.htm:
Vojtášek, F.: Archív celosvetového webu zpřístupněn. In: Ikaros [online]. č. 12/2001.