Aký by mal byť systém metadát na webových sídlach
Krok za krokom|
Úvod V našich článkoch venovaných informačnej architektúre stále zdôrazňujeme, že internet je predovšetkým publikačné médium. Ide o to, akým spôsobom sa obsah dostane k čitateľovi, či mu je prezentovaný dostatočne zrozumiteľným spôsobom a tiež či je obsah nájditeľný. Informačná architektúra ako nová vedná disciplína sa zaoberá mnohými problémami súvisiacimi s organizáciou a usporiadaním informácií v internete tak, aby ľudia dokázali nájsť a efektívne využívať informácie. Podľa Gerryho McGoverna a Roba Nortona (2002) informačná architektúra stojí na štyroch pilieroch: metadáta a klasifikácia, navigácia, vyhľadávanie a dizajn. V predchádzajúcich číslach sme sa podrobne venovali jednotlivým pilierom informačnej architektúry, ako je systém navigácie, vyhľadávania a grafický dizajn. Čo sú metadáta Možno iba súhlasiť s Danielou Ukropovou a Evou Strapcovou (2001), že metadáta sa definujú veľmi ťažko, pretože znamenajú rôzne veci pre rôzne oblasti a rôznych ľudí. Metadáta (metaprvky, metaúdaje) popisujú informačný zdroj. Vo veku internetu sú metadáta informácie, ktoré sa v knižniciach nachádzali vo forme katalógov. Aj keď koncepcia metadát nie je nová a dá sa povedať, že predchádza internet, celosvetový záujem o štandardy metadát narastá až v súvislosti s enormným nárastom internetu, elektronickým publikovaním, vznikajúcimi digitálnymi knižnicami, z čoho aj vyplýva potreba popísať elektronické zdroje štandardizovaným spôsobom, čo zase nesmierne uľahčí vyhľadávanie informácií. Väzba medzi metadátovým záznamom a zdrojom, ktorý popisuje, môže byť v zásade dvojaká:
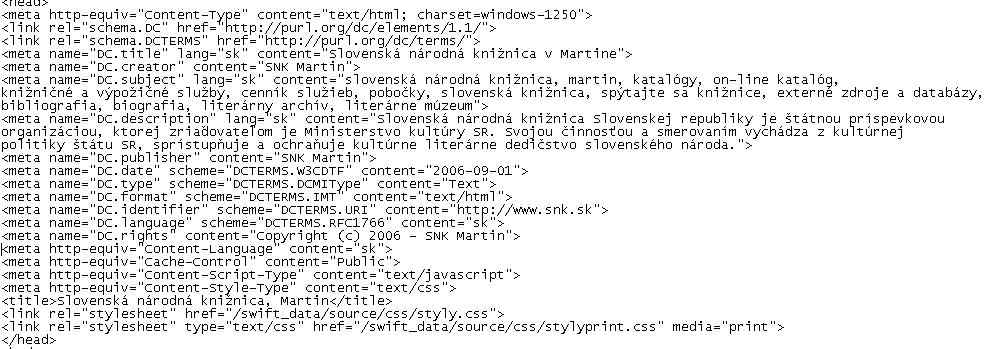
V našom prípade pri tvorbe webových sídiel sú metadáta vnorené priamo do samotného zdroja, a to konkrétne do hlavičky html dokumentu. Príklad: <head> <meta http-equiv=“Content-Type“ content=“text/html; charset=windows-1250″> <meta name=“description“ lang=“sk“ content=“Mestská knižnica pre všetkých obyvateľov Bratislavy ponúka svoje služby a literatúru na špecializovaných pracoviskách.“> <meta name=“keywords“ lang=“sk“ content=“Knižnica, čítanie, knihy, časopisy, dokumenty, katalóg, internet, deti, mládež, literatúra, náučná literatúry, beletria, čítanie“> <meta name=“resource-type“ content=“document“> <meta name=“copyright“ content=“(c) 2005 Mestská knižnica v Bratislave“> <meta name=“author“ content=“SVOP, s.r.o. Bratislava“> <meta name=“robots“ content=“ALL,FOLLOW“> <meta http-equiv=“Content-Language“ content=“sk“> <meta http-equiv=“Cache-Control“ content=“Public“> <meta http-equiv=“Content-Style-Type“ content=“text/css“> <meta http-equiv=“Content-Script-Type“ content=“text/javascript“> <title>Mestská knižnica v Bratislave – Úvodná stránka</title> <link rel=“stylesheet“ href=“styl2.css“> </head> Metadáta môžeme členiť z viacerých hľadísk (Ukropová – Strapcová 2001):
Použitie metadát nie je samoúčelné, hlavné ciele sú:
Metadáta majú aj ďalšiu kľúčovú úlohu v oblasti integrácie a interoperability medzi jednotlivými systémami pracujúcimi s rôznymi formátmi a aplikačnými protokolmi. Gerry McGovern a Rob Norton navrhujú pri návrhu metadát rešpektovať nasledujúce odporúčania (2002, s. 129):
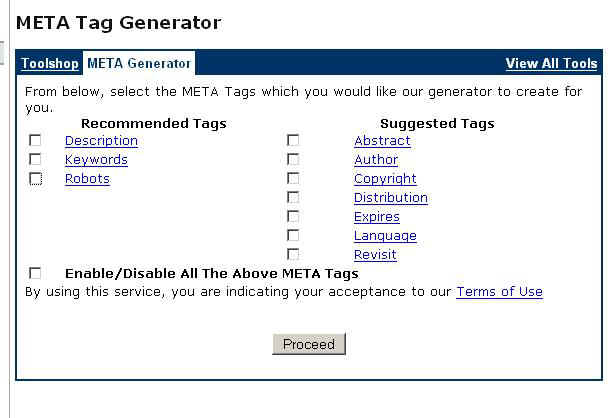
Ako vidíme na obrázku 1, uvedený nástroj umožní vytvoriť veľmi pohodlne metadáta, pričom si vyberieme metadáta, o ktoré máme záujem. Vygenerované metadáta vložíme do hlavičky html dokumentu. K veľmi často používaným metadátam patria tzv. Dublin Core Metadata. Generátor na ich tvorbu nájdeme na URL adrese http://www.webarchiv.cz/generator/dc.php?lang=en. Dublin Core využíva aj Slovenská národná knižnica.
K ďalším odporúčaniam podľa Gerryho McGoverna a Roba Nortona (2002, s. 129) patria:
V súčasnosti sa používajú rôzne formáty; ich popis nájdeme v článku Daniely Ukropovej a Evy Strapcovej (2001), v ktorom uvádzajú, že formáty metadát závisia od zamerania zdrojov a podľa toho môžu mať aj množstvo rozlišovacích parametrov. V prípade popisu jednoduchej www stránky vystačíme s oveľa menej parametrami ako v prípade vysoko štruktúrovaných záznamov zložitých objektov. Požívanie metadát v prípade webových sídiel je skôr na dobrovoľnej báze, často závisí od vedomosti autorov webovských stránok. Využívanie metadát sa skúmalo aj v rámci Projektu charakteristiky webu (Web Characterization Project), ktorý riešil OCLC. Autori projektu konštatovali, že využívanie metadát sa stáva pomerne bežnou záležitosťou. Ale stále väčšinu metadát generujú HTML editory, čo nemá veľký význam pri objavovaní a popise internetovských zdrojov. Ide predovšetkým o metadáta typu content-type, author, generator. Napríklad vytvorenie HTML dokumentu pri využívaní Microsoft FrontPage vytvorí nasledujúce metadáta: <meta http-equiv=“Content-Language“ content=“sk“> <meta http-equiv=“Content-Type“ content=“text/html; charset=windows-1250″> <meta name=“GENERATOR“ content=“Microsoft FrontPage 4.0″> <meta name=“ProgId“ content=“FrontPage.Editor.Document“> Je zrejmé, že tento typ metadát nenesie veľa informácií o samotnom dokumente. Na základe analýzy 1 457 verejných webovských sídiel zistili, že 1 024 sídiel obsahovalo viac ako jeden metaprvok, čo predstavuje 70 %. Celkovo bolo nájdených 2 813 metaprvkov. K najčastejšie používaným metadátam patril Generator (634), Keywords (475), Content-Type (446) Description (422) a Author (155). Porovnanie využitia metadát na úvodných stránkach a interných stránkach Metadáta na prvej úvodnej domovskej stránke by mali popisovať webové sídlo ako celok, zatiaľ čo metadáta na ďalších interných stránkach by mali byť viac špecifické a týkať sa konkrétnej stránky. Je to veľmi výhodné aj pri SEO optimalizácii webového sídla, ak každú časť optimalizujeme pre kľúčové slová, ktoré odrážajú jej obsah. Výsledky analýzy skúmajúce pomer metadát na úvodných stránkach a interných stránkach sú zhrnuté v nasledujúcej tabuľke. Pri analýze sa skúmalo 1452 verejných sídiel.
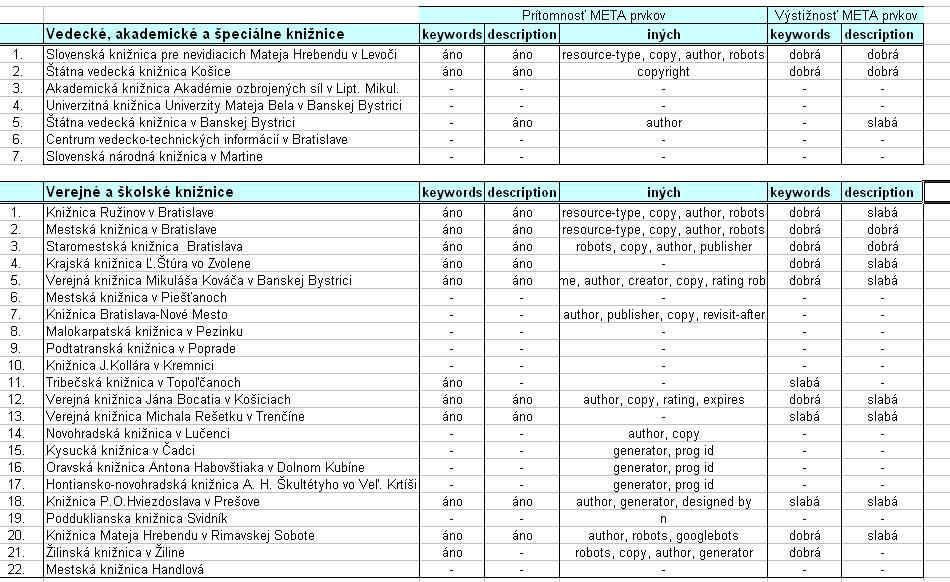
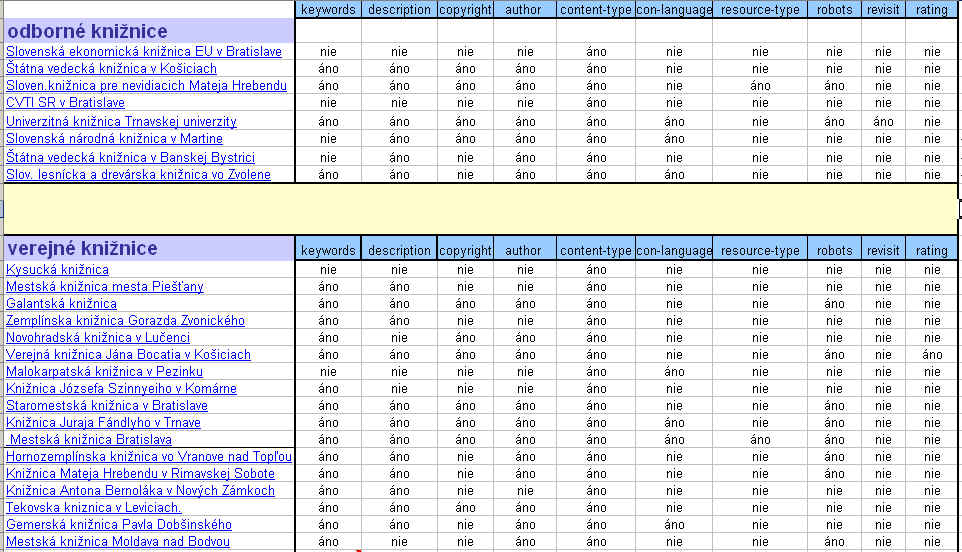
Výsledky ďalej ukázali, že až 20 % sídiel, ktoré obsahovali metadáta na úvodnej aj interných stránkach, jednoducho opakovali tie isté metadáta na každej stránke. Výsledky prieskumu svedčia o tom, že tvorcovia www stránok stále podceňujú metadáta ako nositeľa informácie o obsahu dokumentu. V štúdii Vyhľadávanie informácií v prostredí globálnych počítačových sietí (Makulová 1998) sme analyzovali používanie metadát na slovenskom internete. Išlo o 10 renomovaných slovenských firiem zo Zoznamu slovenského internetu, ktoré sa profesionálne venujú tvorbe internetových stránok a v rámci svojej ponuky ponúkajú komplexné služby. Výsledky prieskumu ukázali, že viac ako polovica firiem neuvádzala žiadne metadáta, iba tie, ktoré vygeneroval profesionálny editor na tvorbu stránok. Podobne titul dokumentu, ktorý je pri tvorbe indexu kľúčový, bol málo výstižný. Väčšinou obsahoval iba nič nehovoriaci názov firmy. Z prieskumu vyplýva, že u nás sa ešte stále neberie do úvahy tvorba stránky ako komplexná tímová práca dizajnera, informačného špecialistu, programátora a odborníka z oblasti interakcie človeka a počítača (Human Computer Interaction). Využívanie metadát analyzovali aj Lawrence a Giles. V známej štúdii Accessibility and Distribution of Information on the Web (1999) konštatujú, že napriek rôznorodosti používaných metaprvkov iba málo z nich popisuje skutočný obsah webovskej stránky. Zo sledovaných 2 500 serverov 34,2 % obsahovalo metadáta ”keyword”. Iba 0,3 % zo sledovaných sídiel obsahovalo štandard Dublin Core. Ukazuje sa, že treba ešte veľmi veľa urobiť v súvislosti so širším nasadzovaním metaprvkov a predovšetkým nového jazyka XML, ktorý umožňuje štruktúrovanie dokumentov a ich popis pri využívaní štandardu Resource Description Framework. To je tiež jeden z dôvodov, prečo sa v rámci World Wide Web konzorcia intenzívne pracuje na vývoji nových nástrojov, ktoré umožnia plne realizovať myšlienku sémantického webu. Ako využívajú na svojich stránkach metadáta slovenské knižnice? Použitie metadát na stránkach slovenských knižníc sme skúmali aj pri vyhodnotení súťaže TOP WebLiB 2005, o čom sme aj podrobne informovali v článku Vyhodnotenie súťaže TOP WebLib 2005 o nalepšie webové sídlo knižnice (Makulová 2006). Situácia bola viac ako neuspokojivá, pretože v tom čase prakticky až 13 z hodnotených knižníc nepoužívalo na svojich stránkach žiadne metadáta, respektíve používalo iba metadáta generované editorom HTML kódu. So študentmi v rámci predmetu metodológia tvorby a hodnotenie webových sídiel pravidelne hodnotíme spĺňanie štandardov W3C slovenskými knižnicami. Na nasledujúcich dvoch obrázkoch vidíme, aká bola situácia v súvislosti s využívaním metadát v apríli 2006 a v apríli 2008. Aj keď sa situácia v porovnaní s predchádzajúcimi rokmi zlepšila, bude zaujímavé porovnať, ako dodržiavajú knižnice webové štandardy v súčasnosti.
Obr. 6 Používanie metadát v slovenských knižniciach v apríli 2008 Záver V súčasnosti sa do popredia čoraz väčšmi dostáva otázka nájditeľnosti webových sídiel. Tak ako kedysi pomáhali katalógy orientovať sa v nesmiernom bohatstve knižníc, dnes hrajú metadáta dôležitú úlohu pri objavovaní a lokalizovaní zdrojov v internete. Aj keď sú na použitie metadát rôzne názory, mali by sme k ich tvorbe pristupovať zodpovedne. Vynaložený čas a námaha sa určite vráti vo zvýšenej návštevnosti webového sídla a lepšej nájditeľnosti.
Literatúra McGOVERN, G. 2002. The Web Content style Guide. London : Pearson Education Limited, 2002. 246 s. ISBN 0 273 65605 8. McGovern, Gerry; Norton, Rob. 2002. Content Critical. London : Pearson Education Limited, 2002. 241 s. MAKULOVÁ, S. 2005. Informačná architektúra a jej vplyv na metodológiu tvorby www stránok. In ITlib. Informačné technológie a knižnice [online], 2005, č. 04 [cit. 2007-10-10]. Dostupné na internete: <http://www.cvtisr.sk/itlib/itlib054/makulova.htm> . ISSN 1336-0779. MAKULOVÁ, S. 2006. Vyhodnotenie súťaže TOP WebLib 2005 o nalepšie webové sídlo knižnice. In ITlib. Informačné technológie a knižnice [online], 2006, č. 02 [cit. 2008-07-07]. Dostupné na internete <http://www.cvtisr.sk/itlib/itlib062/makulova.htm>. ISSN 1336-0779. UKROPOVÁ, D. 2002. Metadáta v slovenských knižniciach. In ITlib. Informačné technológie a knižnice [online], 2002, č. 04 [cit. 2008-07-07]. Dostupné na internete: <http://www.cvtisr.sk/itlib/itlib024/ukropova.htm> UKROPOVÁ, D., STRAPCOVÁ, E. 2001. Metadáta, a čo s nimi. In INFOS 2001. 31. medzinárodné informatické sympózium 2. – 5. apríl 2001, Stará Lesná. [online], 2001, [cit. 2008-07-07]. Dostupné na internete: <http://www.aib.sk/infos/infos2001/34.htm> |