Otvorené archívy – model systémovej interoperability
Hlavné články
Úvod
Teória a prax digitálnych knižníc je v súčasnosti zrejme jednou z najdynamickejšie sa rozvíjajúcich oblastí internetu. Výskumy smerujú k hľadaniu riešení, ktoré by maximálne uľahčili komunikáciu medzi rôznymi systémami, a vychádzajú z premisy, že ak sa už zdroje v digitálnej podobe na počítačovej sieti objavia, je v záujme “globálnej efektívnosti”, aby ich využitie, respektíve využiteľnosť boli čo najširšie.
Jedným z najrozšírenejších konceptov v oblasti teoretických výskumov digitálnych služieb je pojem “otvorenosti” – naznačuje takú architektúru systému či služby, ktorá umožňuje aplikáciu v rôznych oblastiach a zároveň je zárukou spomenutej bezbariérovosti, respektíve minimálnej bariérovosti v komunikácii. V radoch odbornej knižničnoinformačnej verejnosti je už relatívne dobre známy model otvorených archívnych systémov (OAIS), v priebehu posledných dvoch rokov získava čoraz širšiu popularitu iniciatíva otvorených archívov (OAI) ako nástroj publikovania, vyhľadávania a zároveň poskytovania prístupu k digitálnym zdrojom. Napriek tomu, že v názve OAI sa vyskytuje termín archív, treba zdôrazniť, že ide o projekt, ktorý je mimoriadne relevantný aj pre oblasť knižničnoinformačných systémov.
Cieľom tohto príspevku je objasniť základné pojmy, ktoré súvisia s problematikou otvorených archívov – kontextuálne zaradenie pojmu interoperabilita, úloha metadát v koncepcii otvorených archívov a stručný popis funkčných, dátových i procesuálnych charakteristík OAI. Pri spracovaní som vychádzal jednak z dostupnej literatúry, z dôkladnej analýzy pomerne obsiahleho textu protokolu OAI, jednak z poznatkov získaných na základe prednášok a osobných rozhovorov s tvorcami systému.
Interoperabilita a metadáta
V oblasti tradičných automatizovaných informačných systémov, postavených na proprietárnych riešeniach, postupoch a štruktúrach, sa za jedno z hlavných hľadísk efektívnosti fungovania na intersystémovej úrovni považovala a dodnes považuje kompatibilita. Tento pojem sa zvykne definovať ako prepojiteľnosť medzi rôznymi systémami – pôvodne sa chápal predovšetkým ako parameter technický, hardvérový, no v súčasnosti zahŕňa širokú škálu úrovní – technickú, dátovú, lingvistickú atď. (pozri napríklad Makulová, 1993) a dosahuje sa predovšetkým vysokým stupňom dodržiavania dohodnutých pravidiel a postupov, kanonizovaných vo forme noriem a štandardov. Tie sú v knižničnoinformačnej oblasti mimoriadne dôležité najmä z hľadiska dátových štruktúr, keďže umožňujú bezproblémovú výmenu bibliografických i ďalších typov záznamov, ktoré sa v systéme typu KIS využívajú.
S príchodom internetu, digitálnych knižníc, sieťových informačných zdrojov a služieb zabezpečujúcich prístup k týmto zdrojom otázka priamej prepojiteľnosti systémov prestáva byť natoľko aktuálna a čoraz výraznejšie sa do popredia záujmu presúva čiastkový problém, respektíve moderné ponímanie kompatibility, ktoré vyjadruje zmenenú technologickú podstatu komunikácie systémov a ktoré sa najmä v oblasti digitálnych knižníc označuje ako interoperabilita, teda schopnosť spolupracovať – najmä na úrovni dátových štruktúr a prístupových mechanizmov k nim. 1
Ide o mnohorozmerný pojem, ktorý pokrýva také oblasti (Lagoze et al., 2002) ako metadáta, vyhľadávanie sieťových zdrojov, pomenovávanie týchto zdrojov a architektúra služieb. Cieľom interoperability je zvyčajne vybudovať pre používateľov jednoliaty blok služieb z komponentov, ktoré sú vzájomne technicky odlišné a spravujú ich rozličné organizácie (Arms, 2002). Iní autori pod pojmom interoperabilita vidia predovšetkým aspekty digitálnych zdrojov spojené s ich širokou využiteľnosťou, prenosnosťou (medzi sieťami, systémami a organizáciami) a trvanlivosťou – prenosnosťou v čase (Gill, 2002).
Otázky interoperability sa, samozrejme, tiež sústreďujú okolo implementácie spoločných štandardov a strojovej čitateľnosti dát. 2 Z tohto hľadiska úspech môžu očakávať najmä také riešenia, ktoré poskytujú potrebnú funkčnosť a ktorých aplikácia nie je komplikovaná a najmä finančne náročná – tak ako to potvrdili skúsenosti z predchádzajúceho desaťročia vývoja webu s takými technológiami, ako je protokol HTTP alebo značkovací jazyk HTML.
Dôležité miesto v koncepcii interoperability systémov, či presnejšie niektorých jej úrovní, zohrávajú metadáta, ktoré sa čoraz nástojčivejšie posúvajú do pozície základného komunikačného nástroja webu. Ide o údaje, ktoré popisujú obsahové, formálne či iné charakteristiky iných, “primárnych” údajov vo forme viac alebo menej uzatvorenej množiny atribútov s definovanou sémantikou a syntaxou. Vytváranie sekundárnych informácií nie je pre pracovníkov knižničnoinformačných inštitúcií žiadnou novinkou, v digitálnom prostredí však táto činnosť vykazuje v porovnaní s tradičnou katalogizáciou niekoľko podstatných odlišností:
- vyšší stupeň distribúcie spracovania – jednak medzi knižnicami, ktoré v rámci rôznych programov (OCLC InterCat, CORC, BIBLINK a iné projekty) spolupracujú pri tvorbe databáz popisov digitálnych zdrojov, jednak tiež vďaka faktu, že na tvorbe metadát sa do značnej miery podieľajú samotní tvorcovia primárnych zdrojov;
- vyšší stupeň zapojenia iných “agentov” – často sa komerčné informačné inštitúcie podieľajú na tvorbe popisov vo forme detailnejších metadát pre potreby špecifických používateľských skupín (odborové systémy a pod.), prípadne sa v jednoduchších prípadoch realizuje automatický výber popisnej informácie z HTML metatagov, XML tagov a pod.;
- forma metadát je často taká istá ako forma primárnych prameňov – štrukturácia podľa pravidiel niektorého zo značkovacích jazykov;
- metadáta sú často priamo súčasťou primárnych zdrojov, alebo sú s nimi veľmi úzko prepojené.
Komplexnosť problematiky metadát vystúpi ešte viac do popredia, keď si uvedomíme ich využitie nielen v oblasti popisu zdrojov (teda v oblasti, ktorá je tradičnou knihovníckou doménou), ale aj v ďalších oblastiach spojených so životným cyklom digitálnych zdrojov. Na základe týchto rozličných funkcií sa metadáta aj zvyknú členiť na niekoľko typov. Najčastejšie sa spomínajú tri skupiny – deskriptívne, štrukturálne a administratívne; niektoré typológie spájajú deskriptívne a administratívne metadáta do jednej skupiny a vyčleňujú potom typologické skupiny syntaktických a sémantických metadát. Zatiaľ čo syntaktické (štrukturálne) metadáta sa využívajú na definovanie štrukturálnych vzťahov v rámci jedného dokumentu alebo medzi dokumentmi (napríklad metadáta v zmysle tagov definujúcich štrukturálne prvky dokumentu v jazyku XML), sémantické metadáta zahŕňajú širokú škálu údajov, ktorých úlohou je popis digitálnych zdrojov na účely vyhľadávania, ale aj administratívneho spravovania – sem môžeme zaradiť známe metadátové koncepcie a schémy, ako sú TEI (Text Encoding Initiative), DC (Dublin Core), WF (Warwick Framework), RDF (Resource Description Framework), DOI (Digital Object Identifier) či OCLC/RLG Preservation Metadata. 3
OAI – Open Archives Initiative
Iniciatíva otvorených archívov je ďalšou iniciatívou z oblasti digitálnych knižníc, ktorá má vo svojom názve termín “archív”. Vznikla na pôde aktívnej skupiny Digital Library Research Group a venovali sa jej od počiatkov najmä dvaja odborníci na problematiku sieťovej komunikácie – Carl Lagoze a Herbert van de Sompel. Na rozdiel od OAIS (Open Archival Information System), ktorý na konceptuálnej úrovni pokrýva technologické procesy digitálnej knižnice ako systému zabezpečujúceho získavanie, spracovávanie, uchovávanie a sprístupňovanie digitálnych zdrojov (najmä v zmysle primárnych dokumentov), koncept OAI sa sústreďuje najmä na prístup k dátam, na limitované rešeršné funkcie realizované cez metadáta.
Pôvod iniciatívy OAI je v oblasti elektronického publikovania, predovšetkým odborného – pod pojmom archív sa primárne rozumie “sklad” vedeckých/odborných článkov a štúdií, ktoré sú určené na šírenie v rámci odbornej komunity. Otvorenosť sa chápe na úrovni systémovej architektúry v zmysle definovania takých rozhraní, ktoré umožňujú prístup k dátam rôznych producentov. Rozhodne však tento pojem nemožno interpretovať ako možnosť neobmedzeného a absolútne voľného, resp. bezplatného prístupu – otázka zabezpečenia, verifikácie a kontroly prístupu však nie je predmetom riešenia v rámci modelu OAI.
Základným procesom OAI, prostredníctvom ktorého sa zabezpečuje systémová interoperabilita, je zber metadát (anglicky metadata harvesting). Ide o (selektívne) sústreďovanie metadát z viacerých zdrojov do jedného centra. Na fungovaní architektúry OAI participujú dva typy účastníkov: poskytovatelia dát a poskytovatelia služieb. Poskytovatelia dát “vystavujú” vo forme metadátových repozitárov svoje metadáta cez otvorené rozhrania, poskytovatelia služieb pomocou OAI protokolu formulujú svoje požiadavky a nájdené metadáta využívajú ako základ pre vývoj nadstavbových služieb, napríklad obohacovaním o nové typy metaúdajov (také, ktoré sú špecifické pre určitú odborovú skupinu či oblasť) a ich sprístupňovaním cez vlastné rešeršné rozhrania a služby, portály (obr. 1).
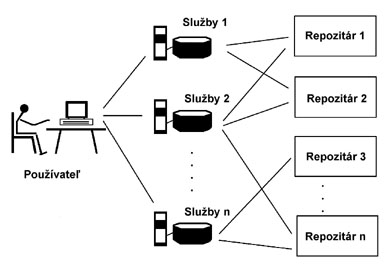
Obrázok 1 Funkčná schéma systému OAI
Pod pojmom repozitár sa rozumie sieťovo dostupný server, prípadne skupina serverov, ktorému je možné zasielať požiadavky formulované podľa pravidiel protokolu OAI. Tento pojem však v kontexte OAI rozhodne nie je nový – použili ho už v polovici 90. rokov viacerí autori pracujúci v oblasti teórie budovania digitálnych knižníc v rámci americkej Corporation for National Research Initiatives. Celá koncepcia OAI je vlastne do značnej miery zhodná s rámcovými princípmi pre distribuované služby digitálnych objektov (Kahn, 1995, Arms, 1995), z ktorých mnohé sa medzičasom premietli do všeobecne akceptovaných a využívaných princípov výstavby a fungovania digitálnych knižníc. 4
V snahe o terminologické precizovanie problematiky autori zaviedli aj ďalšie, dnes už bežne používané termíny – digitálny objekt, rukoväť (“handle” ako nástroj identifikácie objektu bez ohľadu na jeho lokalizáciu), obsah digitálneho objektu, ktorý sa rozčleňuje na dátovú a metadátovú zložku. 5 V súvislosti s pojmom repozitár je v koncepcii OAI a CNRI jeden podstatný rozdiel – zatiaľ čo podľa CNRI sa tu ukladajú kompletné digitálne objekty, teda dáta spolu s “ich” metadátami, v štruktúre otvorených archívov je podstata objektu – aký typ metadát je skutočne uložený v objekte, aký typ metadát sa generuje podľa potreby automaticky, či objekt zahŕňa aj primárny obsah, ktorý metadáta popisujú – mimo zorného uhla protokolu OAI.
OAI a metadáta
Ďalším nástrojom dosiahnutia interoperability v rámci systému OAI je dohoda o popise zdrojov. Za najmenší spoločný menovateľ boli zvolené metadáta na úrovni nekvalifikovaného Dublin Core – jednak kvôli zabezpečeniu jednoduchosti pri tvorbe popisu tak, aby ho mohli bez väčších problémov zrealizovať samotní autori či vydavatelia, jednak tiež s ohľadom na skutočnosť, že proces kvalifikovania vnáša do popisu zdrojov a ich následného vyhľadávania komplikácie spojené s interpretáciou významu jednotlivých prvkov. Kvalifikácia je zložená z mechanizmov umožňujúcich pridávať sémantickú špecifickosť prvkom v štruktúre DC.
Dnes už historický rozpor medzi minimalistickým a štrukturalistickým prístupom vo vývoji DCMES (Dublin Core Metadata Element Set), teda medzi prúdmi vystupujúcimi proti, respektíve v prospech využívania kvalifikátorov, sa napokon vyriešil kompromisne. Je však zrejmé, že DC sa podľa koncepcie otvorených archívov (ale nielen podľa nej) úspešne uplatní najmä vo svojom primárnom určení, teda ako nástroj vyhľadávania, identifikácie relevantných zdrojov na základe “hrubých” popisných atribútov, vo forme “nesyntaktických reprezentácií” (Lagoze, 2000). V prípade potreby podrobnejšieho, odborovo špecifického popisu je možné do metadát zakomponovať aj iné metadátové schémy na základe podpory paralelných setov podľa princípov zásobníkovej architektúry modelu RDF.
Dátová štruktúra OAI je postavená na tvorbe záznamov, ktoré repozitár vracia ako odpoveď na požiadavku v protokole OAI a ktoré sú kódované podľa pravidiel XML a slúžia ako “obal” pre metadáta popisujúce jednotlivý digitálny objekt/dokument v rámci repozitára (obr. 2). Každý záznam môže mať 3 zložky:
1. záhlavie (header) – obsahuje informácie, ktoré sú spoločné pre všetky záznamy a ktoré sú nevyhnutné pre proces zberu. Sú to informácie nezávislé od formátu metadát, ktoré sú obsiahnuté v samotnom zázname. Člení sa na 2 údajové prvky:
- identifikátor záznamu v konkrétnom repozitári – slúži ako kľúč pre výber metadát z objektu v repozitári;
- dátumová známka – vypovedá o čase vytvorenia, modifikácie, respektíve vymazania objektu;
2. metadáta – popis zdroja v určitom metadátovom formáte, konkrétny požadovaný formát je možné zadať ako argument v príkazoch OAI;
3. (about) – nepovinná časť, ktorá obsahuje údaje o metadátach (práva k vytvorenému metadátovému záznamu, podmienky či obmedzenia jeho použitia a pod.).
|
<header> Obr. 2. Ukážka záznamu v štruktúre OAI (podľa Lagoze, C. – Van de Sompel, H., 2001) |
Na uvedenom príklade sú zreteľne čitateľné základné princípy vytvárania záznamov metadát podľa pravidiel XML a RDF. Párové tagy (úvodný a záverečný), ktoré označujú štrukturálne časti záznamu a ktoré sú vlastne tiež formou metadát, presná špecifikácia schémy alebo “menného priestoru” (anglicky namespace, v ukážke reprezentovaný príkazom dc xlmns) ako množina preddefinovaných prvkov a ich atribútov (či už je to DC, UNIMARC alebo iný systém), na základe ktorých sú popisné metadáta vytvorené. Všimnime si, že v zázname sú dva prvky označené ako identifier. Ten prvý, v záhlaví, identifikuje záznam, druhý v metadátovej časti záznamu slúži na identifikáciu digitálneho objektu, ktorý je predmetom popisu.
Procesy OAI
Dôležitým aspektom procesuálnej charakteristiky OAI je zber metadát na základe jednoduchej selekcie – je evidentné, že zber údajov bez možnosti výberu by viedol k neefektívnemu fungovaniu systému, pri ktorom by klient sťahoval z repozitára opakovane stále dokola tie isté záznamy. Model OAI preto umožňuje špecifikovať určité podmnožiny záznamov na základe dvoch charakteristík – dátumu (prostredníctvom dátumovej známky v záhlaví záznamu) a záznamovej sady, čo je producentom definovaná, ľubovoľná podmnožina záznamov v repozitári (napríklad tematická). V súvislosti so sadami platí pravidlo, že každý objekt v repozitári môže byť zaradený do jednej, niekoľkých sád, alebo nemusí byť zaradený v žiadnej sade.
Komunikácia medzi účastníkmi systému sa realizuje pomocou špeciálneho protokolu OAMHP (Open Archives Metadata Harvesting Protocol), na báze webového HTTP. Typická implementácia využíva štandardný webový server, ktorý je nakonfigurovaný na prerozdeľovanie požiadaviek OAI ďalšiemu softvéru, ktorý tieto požiadavky ďalej spracováva.
Štruktúra jednotlivých komunikátov (požiadaviek) podľa špecifikácií OAI má dve časti: URL repozitára + argument (príkaz).
Aktuálna verzia protokolu (1.1 z 20010702) 6 rozoznáva dve skupiny príkazov – zberové (1 – 3), ktoré slúžia na vlastný zber metadát, a informačné (4 – 6), pomocou ktorých sa zisťujú informácie o repozitári a jeho vlastnostiach:
1. GetRecord – vyhľadanie individuálneho záznamu metadát na základe konkrétneho identifikátora. Okrem identifikátora tento príkaz musí obsahovať argument určujúci vyžadovaný formát metadát (metadataPrefix).
2. ListRecords – zber záznamov z repozitára. Povinným argumentom je aj v tomto prípade vyžadovaný formát metadát. Voliteľné argumenty umožňujú selektivitu zberu na základe dátumu (vytvorenie, modifikácia či vymazanie objektu v určitom časovom horizonte), respektíve príslušnosti do sady príbuzných záznamov (set).
3. ListIdentifiers – vyhľadanie všetkých identifikátorov objektov, ktorých metadáta možno z repozitára zberať – príkaz je možné obmedziť pomocou voliteľných argumentov špecifikujúcich dátum a sadu.
4. Identify – vyhľadanie informácií o repozitári (názov, URL, podporovaný OAI protokol, emailová adresa administrátora, metadátová a dátová politika a pod.).
5. ListMetadataFormats – vyhľadanie všetkých formátov metadát, ktoré sa používajú v repozitári. Ako voliteľný argument možno použiť identifikátor objektu, ktorý obmedzí požiadavku na metadátové formáty dostupné pre konkrétny záznam.
6. ListSets – vyhľadanie setovej štruktúry repozitára, teda informácia o tom, do akých tematických či iných skupín sú objekty v repozitári rozdelené.
Spôsob implementácie príkazov a argumentov protokolu OAI do štruktúry HTTP možno vidieť aj na nasledujúcom príklade:
http://an.oa.org/OAIscript?
verb=GetRecord&identifier=oai:arXiv:quantph/9901001&metadataPrefix=oai_dc
Prvý riadok obsahuje URL adresu repozitára, ktorému je požiadavka určená, v druhom riadku (presnejšie po znaku?) nasleduje kompletný príkaz na získanie záznamu o objekte (špecifikovaný identifikátorom) v štruktúre popisu podľa Dublin Core – jednotlivé argumenty sú oddelené znakom &.
Otvorenosť architektúry OAI okrem iného spočíva aj v tom, že záujemcovia môžu participovať na fungovaní systému na rôznych úrovniach. Od jednoduchého, “neregistrovaného” využívania protokolu na zverejňovanie či zber metadát až po plne registrovanú účasť, pri ktorej sa využíva registrovaný menný priestor OAI a identifikácia záznamov sa realizuje v súlade s konvenciou OAI. Táto konvencia, ako ukazuje obrázok 2, definuje štruktúru identifikátora ako trojzložkový údaj, ktorého jednotlivé zložky sú oddelené dvojbodkou (oai:arXiv:9901001) – v súlade so štruktúrou služieb typu URI (Uniform Resoure Identifier) definovanou v RFC 2396 ( http://www.ietf.org/rfc/rfc2396.txt). Prvá časť identifikuje menný priestor (oai), druhá jednoznačne označuje archív a tretia záznam v rámci archívu. Výhodou tohto prístupu je fakt, že s podporou adresnej služby (resolution service) OAI možno identifikátor záznamu použiť ako URN na presnú identifikáciu a nájdenie zdroja aj v prípade zmeny jeho sieťovej lokácie, podobne ako s využitím iných služieb tohto či podobného typu (DOI, PURL a pod.).
Projekty vychádzajúce z OAI
Protokol v súčasnosti využíva väčšie množstvo organizácií. Pod akronymom arXiv sa skrýva archív vedeckých publikácií prevažne z oblasti prírodných vied, ktorý sa buduje s podporou U.S. National Science Foundation na Cornell University. Na prevádzku svojho servera a funkčnosť protokolu OAI využíva softvér eprints ( http://www.eprints.org), ktorý podporuje vytváranie webových archívov dokumentov a príslušných metadát a bol vytvorený na Univerzite v Southamptone.
Open Archive Forum ( http://www.oaforum.org) je iniciatíva “sprievodných opatrení”, ktorú financuje Európska komisia a jej cieľom je podpora projektov, ktoré sa zaujímajú o aplikáciu modelu OAI. Na účely komfortného vyhľadávania zdrojov dostupných vo vybranej množine archívov pracujúcich v prostredí OAI bol v marci 2002 sprístupnený portál my.OAI ( http://www.myoai.com).
Jednou z najrozsiahlejších plánovaných aplikácií protokolu je projekt National Digital Library for Science Education (NSDL). Vlastný repozitár knižnice, ktorý sa má budovať ako centrálny metadátový sklad systému, ráta so štyrmi typmi “akvizície” metadát – zberom z rôznych dostupných zdrojov (iných repozitárov) s využitím protokolu OAI; zhromažďovaním, automatickým generovaním metadát z voľne dostupných webových zdrojov; priamym zasielaním metadát z rôznych fondov prostredníctvom protokolov FTP, emailu či webuploadu; alebo priamym zápisom záznamov z prostredia participujúcich inštitúcií (Lagoze, 2002).
Čerstvou a pomerne významnou inováciou v rodine aplikácií otvorených archívov je ďalší softvér Kepler ( http://kepler.cs.odu.edu), ktorý čiastočne modifikuje architektúru OAI a umožňuje prevádzku menších archívov (v terminológii systému označované ako archivelet), napríklad na osobných počítačoch vedeckých pracovníkov. Nainštalovaním softvéru na osobný počítač sa používateľ automaticky stáva účastníkom komunity, pre ktorú centrálny registračný server eviduje umiestnenie všetkých spoločne využívaných objektov na všetkých pripojených počítačoch a eviduje tiež v každom okamihu všetky aktívne klienty (podobná filozofia pred pár rokmi nechvalne preslávila Napster). Vytvára sa tak pomerne veľké množstvo prepojených, OAIrelevantných miniarchívov, pričom problém nestálosti pripojenia sa musí riešiť práve dominantnejšou registračnou službou (obr. 3). Základným služobným prvkom systému Kepler je rešeršná službaserver Arc ( http://arc.cs.odu.edu), ktorá vlastne spája všetky registrované miniarchívy a jej prostredníctvom sa tieto javia ako jedna veľká digitálna knižnica.
|
|
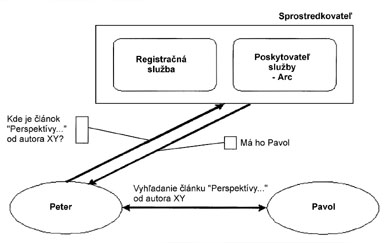
Obr. 3 Funkčná schéma systému Kepler na základe modelu siete peer-to-peer (podľa Maly, 2001)
Jedným z posledných potvrdení perspektívnosti smerovania idey otvorených archívov je takzvaná Budapeštianska iniciatíva otvoreného prístupu, ktorá vznikla vo februári 2002 na pôde Open Society Foundation (Budapest Open Access Initiative – http://www.soros.org/openaccess/read.shtml) a ktorá sa formuje ako snaha o presadenie myšlienky otvoreného prístupu k odborným informáciám a vedeckým poznatkom na základe prekonania skostnateného systému odborného publikovania, najmä vedeckých časopisov. Na dosiahnutie ideálu otvoreného prístupu navrhuje dokument dve riešenia – vytvorenie novej generácie alternatívnych vedeckých časopisov a využívanie metódy individuálneho sebaarchivovania aplikáciou metód a nástrojov, ktoré vychádzajú z myšlienok a štandardov presadzovaných v rámci OAI.
Záver
Ako vidieť z predchádzajúcej kapitoly, model OAI si za pár rokov existencie už našiel pomerne širokú škálu aplikácií a, čo je ešte dôležitejšie, aj niekoľko praktických softvérových realizácií. S ich využitím sa pre každú knižnicu, ktorá nastúpila na cestu digitalizácie fondov, otvára možnosť ponúknuť digitálne objekty na kooperatívne využívanie do prostredia globálnej siete. Na základe tvorby popisov zdrojov v štruktúre Dublin Core a s minimálnou infraštruktúrou sa tak fond ktorejkoľvek knižnice na Slovensku, alebo aspoň jeho vybraná časť (napríklad digitalizované staré a vzácne tlače), môže dostať do ponuky zdrojov niektorého poskytovateľa služieb a stať sa tak súčasťou celosvetovej digitálnej knižnice.
Poznámky:
1. Internetová encyklopédia Whatis ( www.whatis.com) definuje interoperabilitu ako schopnosť systému alebo produktu pracovať s inými systémami alebo produktmi bez potreby vynaložiť zvláštnu námahu zo strany používateľa. Miller ju charakterizuje ako posun od proprietárne monolitických, uzatvorených systémov smerom k princípom otvorenosti, spoločného využívania a prístupu (Miller, 2000).
2. V kontexte riešenia amerického projektu NSDL, ktorý je spomenutý nižšie, autori uvádzajú tri druhy, respektíve úrovne spolupráce v rámci snahy o dosiahnutie interoperability. Federácia je najsilnejšou formou, pri ktorej sa skupina organizácií dohodne, že ich služby budú vyhovovať určitým špecifikáciám, zväčša na úrovni formálnych štandardov. Keďže cena participácie je pomerne vysoká, typické federácie majú zvyčajne početne malé, ale zato aktívne členstvo. Dátový zber (harvesting) je voľnejšie zoskupenie digitálnych knižníc, v rámci ktorého sa účastníci dohodnú na minimálnom úsilí, na základe ktorého budú môcť realizovať niektoré základné spoločné služby (viď OAI). Zhromažďovanie dát (gathering) je úrovňou interoperability, pri ktorej organizácie nijako formálne nespolupracujú, len vzájomne využívajú svoje dáta, ktoré je možné voľne zhromaždiť z internetu pomocou robotov (web crawler) – pozri napríklad Arms, 2002.
3. Detailnejší pohľad na metadáta z hľadiska ich typológie a štruktúry v súvislosti s technologickými procesmi životného cyklu dokumentu, najmä však so zameraním na archívne uloženie a vyhľadávanie, ponúka dokument OCLC/RLG, 2001.
4. Tých princípov je osem a v stručnosti ich možno formulovať takto:
- Technický rámec digitálnej knižnice existuje v rámci konkrétnych legislatívnych a sociálnych podmienok.
- Porozumenie základných pojmov digitálnej knižnice do značnej miery sťažuje terminologická nejednotnosť.
- Technická architektúra systému by mala byť oddelená od obsahu, ktorý je uložený v knižnici.
- Názvy a identifikátory sú základným stavebným blokom pre digitálnu knižnicu.
- Objekty digitálnej knižnice sú viac ako len množiny bitov.
- Objekt digitálnej knižnice v procese využívania je odlišný od objektu, ktorý je uložený v repozitári.
- Repozitáre sa musia starať o informácie, ktoré sú v nich uložené.
- Používatelia chcú intelektuálne diela, nie digitálne objekty (podľa Kahn, 1995).
5. Dátová štruktúra ráta s možnosťou zoskupovania objektov a ich vyhľadávania. Jedným z prístupov riešenia tohto problému je vytvorenie digitálneho objektu, ktorý obsahuje niekoľko ďalších objektov – tým by sa napríklad dalo dosiahnuť to, že viaceré formáty textu by mohli byť sústredené v jednom objekte. Druhou alternatívou je separátna existencia jednotlivých objektov s vlastnými identifikátormi – tieto identifikátory je možné uložiť do samostatného digitálneho objektu, metaobjektu, ktorý v podstate plní úlohu “katalogizačného záznamu” (Arms, 1995).
6. Správy z webservera OAI z dňa 8. apríla uvádzajú, že verzia protokolu 2.0 je pripravená na zverejnenie k 1. júnu 2002, pričom medzi testovateľmi betaverzie sa nachádzajú také inštitúcie ako OCLC, British Library, NASA, UKOLN, Cornell University či Ex Libris.
Zoznam bibliografických odkazov a odporúčané zdroje:
ARMS, W. Y. 1995. Key Concepts in the Architecture of the Digital Library. In DLib Magazine [online]. July 1995. http://www.dlib.org/dlib/July95/07arms.html.
ARMS, W. Y. et al. 2002. A Spectrum of Interoperability. The Site for Science Prototype for the NSDL. In DLib Magazine [online]. 8(1), January 2002. http://www.dlib.org/dlib/january02/arms/01arms.html.
GILL, T. – MILLER, P. 2002. Reinventing the Wheel? Standards, Interoperability and Digital Cultural Content. In DLib Magazine [online]. 8(1), January 2002. http://www.dlib.org/dlib/january02/gill/01gill.html.
HAKALA, J. 2001. Document Description and Access – New Challenges. In Sborník ze semináře CASLIN 2001 [online]. http://www.caslin.cz:7777/caslin01/sbornik/hakala.html.
KAHN, R., WILENSKY, R. 1995. A Framework for Distributed Digital Object Services [online]. May 1995. http://www.cnri.reston.va.us/home/cstr/arch/kw.html.
LAGOZE, C. 2000. Accommodating Simplicity and Complexity in Metadata : Lessons from the Dublin Core Experience [online]. Presented at Seminar on Metadata, June 8, 2000. http://www.cs.cornell.edu/lagoze/Papers/dc.pdf.
LAGOZE, C., VAN DE SOMPEL, H. 2001. The Open Archives Initiative : Building a LowBarrier Interoperability Framework [online]. http://www.openarchives.org/documents/oai.pdf.
LAGOZE, C. (ed.). 2002. Core Services in the Architecture of the National Digital Library for Science Education (NSDL) [online]. arXiv, http://arxiv.org/abs/cs.DL/0201025.
MAKULOVÁ, S. 1993. Automatizácia knižníc – problémy, východiská, postupy. Bratislava : Stimul 1993. 298 s.
MALY, K., ZUBAIR, M., LIU, X. 2001. Kepler – an OAI Data/Service Provider for the Individual. In DLib Magazine [online]. 7(4), April 2001. http://www.dlib.org/dlib/april01/maly/04maly.html.
MILLER, P. 2000. Interoperability : What is it and Why shouldI want it? In Ariadne [online]. Issue 24. http://www.ariadne.ac.uk/issue24/interoperability/intro.html.
NICHOLS, B. 2002. Open Meta Tools. In BYTE Magazine [online]. Feb 2002. http://www.byte.com/documents/s=7023/byt1014229948533/0225_nicholls.html.
OCLC/RLG Working Group on Preservation Metadata. 2001. Preservation Metadata for Digital Objects : A Review of the State of the Art. White Paper. [online]. http://www.oclc.org/digitalpreservation/presmeta_wp.pdf.
VAN DE SOMPEL, H., LAGOZE, C. 2001. The Open Archives Initiative Protocol for Metadata Harvesting [online]. http://www.openarchives.org/OAI/openarchivesprotocol.html.