Nevyhnutné podmienky pri tvorbe digitálnych knižníc
NISPEZ predstavuje|
Čo robíme v pamäťových a fondových inštitúciách? Pamäťové a fondové inštitúcie (ďalej PFI) sa v svojej činnosti zameriavajú predovšetkým na získavanie, ochranu, spracovanie a sprístupňovanie objektov kultúrneho dedičstva. Z iného uhla pohľadu môžeme odborné činnosti PFI (predovšetkým archívov, knižníc, múzeí, galérií, ale i ostatných) rozdeliť do dvoch základných oblastí. Prvou je objavovanie a zhromažďovanie rôznorodých primárnych materiálov a podkladov vypovedajúcich o našej minulosti aj o súčasnom živote. Druhá oblasť predstavuje systematickú prácu zameranú na dokumentovanie týchto materiálov. Samotná dokumentácia však väčšinou predstavuje už len výsledky odbornej vedeckej a výskumnej práce pracovníkov týchto inštitúcií, ktorí skúmajú význam a jedinečnosť jednotlivých predmetov z hľadiska historického kontextu spoločnosti a jej vývoja. Spracovanie objektov kultúrneho dedičstva sa v jednotlivých typoch PFI riadi svojimi vlastnými pravidlami a legislatívou. Z pohľadu webu a súčasných technológií je nevyhnutné zaoberať sa nielen samotným spôsobom spracovania, ale predovšetkým prístupom k spracovaniu. Čo na to využívame? Z historického hľadiska majú v spracovaní a organizovaní informačných zdrojov (dokumentov) najdlhšiu tradíciu knižnice. Vzhľadom na to, že údaje majú byť strojom čitateľné, aby ich bolo možné prezentovať v elektronickej podobe, ich spracovanie sa riadi štandardmi a odporúčaniami, ktoré boli vytvorené a prijaté väčšinou na medzinárodnej úrovni. Jednotlivé typy PFI majú svoje profesijné organizácie a združenia, ktoré zastrešujú tvorbu štandardov a odporúčaní. Z pohľadu spracovania je dôležitých niekoľko typov štandardov a odporúčaní, ktorými sa pracovníci PFI riadia, alebo by sa riadiť mali. Najznámejšia je typológia štandardov z hľadiska obsahu na:
V prvej skupine, teda medzi štandardami a odporúčaniami určujúcimi syntax záznamu a princípy výmeny a komunikácie dát, ide predovšetkým o metadátové schémy, ako sú MARC – UNIMARC a MARC21, a to pre všetky oblasti popisu vrátane autorít. Na tomto mieste je vhodné pripomenúť pojem autority, ktorý bol zavedený a značne rozšírený predovšetkým v súvislosti s automatizáciou. Autority predstavujú unifikované selekčné prvky s nevyhnutným odkazovým a poznámkovým aparátom1. K autoritám sa neskôr v článku vrátime v iných súvislostiach. Podobne ako knižnice majú aj ostatné typy PFI definované svoje metadátové schémy a pravidlá. Sú to predovšetkým CDWA, VRA Core, EAD, EAC-CPF. Do druhej skupiny zaraďujeme štandardy a odporúčania určujúce sémantiku záznamu a spracovateľskú prax. V súvislosti s knižnicami hovoríme dnes o Anglo-amerických katalogizačných pravidlách – AACR2. Pre oblasť spracovania kultúrnych objektov je známy štandard CCO a pre archívy sú to štandardy ISAD(G), ISAAR(CPF) a iné. Čo získame? Okrem samotného procesu dokumentačnej činnosti a pravidiel, ktorými sa riadia, je potrebné spomenúť aj výsledky a výstupy tejto činnosti, najmä ak chceme uvažovať o prezentačnej vrstve informačných systémov v pamäťových a fondových inštitúciách. Výsledkom dokumentačnej činnosti sú predovšetkým rôzne katalógy a registre. Práve v snahe o vytvorenie atraktívnej prezentácie kultúrneho dedičstva, uchovávaného v PFI pre verejnosť, sa katalógy a registre cielene dopĺňajú a rozširujú o rôzne formy vizualizácie objektov. V opozícii k týmto výsledkom dokumentačnej činnosti stojí web – fenomén, ktorý z pohľadu PFI mal prispieť predovšetkým k rozšíreniu využívania internetu a tým k uľahčeniu, zrýchleniu, viacnásobnému zdieľaniu a sprístupňovaniu práce knihovníkov, kurátorov, archivárov a ostatných pracovníkov týchto inštitúcií. Z letmého pohľadu do histórie je zrejmé, že sme niekoľkokrát zmenili nástroje a prostriedky pre tvorbu informačných zdrojov. Pri kritickom pohľade však zistíme, že sa tieto zmeny neodrazili na našom prístupe k spracovaniu. Stále sa riadime paradigmou, ktorá vznikla ešte v čase, keď sme o súčasných nástrojoch a prostriedkoch na spracovanie mohli len snívať. Práve tu je základ problémov, ktoré dnes riešia mnohé tímy odborníkov a výskumníkov. Máme problém prepojiť vlastné zdroje (a tým myslíme zdroje dostupné v rámci inštitúcie, v rámci jedného typu inštitúcií), nehovoriac o zdrojoch naprieč všetkými PFI. Prepojené zdroje by mohli byť v súčasnom prostredí webu využívané oveľa viac a efektívnejšie. Stojí pred nami i ďalší problém, a tým je spracovanie obrovského množstva objektov, ktoré prakticky v tomto prostredí v digitálnej podobe vznikajú vo veľkom počte. Sú medzi nimi formálne štruktúrované dokumenty, zbierky multimediálnych objektov, údaje v databázach, ale aj dokumenty bez akejkoľvek formálnej štruktúry. Prostredie webu a možnosti súčasných technológií do značnej miery ovplyvňujú aj našich používateľov, a preto sa ich požiadavky dramaticky menia. Ak si chceme zachovať ich priazeň, je nevyhnutné na ne čím skôr reflektovať. Dobrým znamením je fakt, že v medzinárodnom kontexte si túto zmenu už dlhodobejšie uvedomujeme. Knihovníci – znova ako prví – v tejto súvislosti definovali tzv. „funkčné požiadavky“. Konkrétne ide o FRBR – funkčné požiadavky na bibliografické záznamy, po ktorých nasledovali FRAD – funkčné požiadavky na záznamy autorít (so zameraním predovšetkým na menné autority), a v riešení sú tiež FRSAD – funkčné požiadavky na vecné autority. Dokonca poznatky nadobudnuté pri definovaní týchto požiadaviek viedli knihovníkov k tomu, že je nutné redefinovať aj základné pravidlá. Ešte stále sa pri spracovaní odporúčajú pravidlá AACR2, ktorých história siaha do minulého storočia, do obdobia, keď internet len vznikal. Od tých čias boli viackrát tieto pravidlá aktualizované, ale nikdy nie radikálne. K takejto radikálnej zmene katalogizačných pravidiel malo prísť vydaním nových pravidiel – označovaných ako RDA (Resource Description and Access). Ich prvé vydanie bolo pôvodne ohlásené na máj minulého roka, tento termín sa však viackrát posúval a podľa webovej stránky tohto projektu http://www.rda-jsc.org/rda.html by mali byť vydané v júni tohto roku. Možno na základe týchto pravidiel bude jasnejšie, že je najvyšší čas zmeniť náš prístup k spracovaniu a viac pri tom rešpektovať zmeny, ktoré so sebou prináša i prostredie webu, pretože práve web je v centre pozornosti používateľov a stal sa aj akousi hybnou silou pre ďalší rozvoj budúcich technológií. Internet a web spolu nielenže potierajú hranice medzi geografickými územiami, ale odstraňujú aj bariéry a hranice medzi jednotlivými inštitúciami a to na vertikálnej, ale i horizontálnej úrovni. Dnešný používateľ, ktorý je zvyknutý na prostredie webu takmer na každom kroku, sa v prípade pátrania po informáciách z oblasti kultúrneho dedičstva nechce a nebude zaoberať tým, čo v svojich katalógoch a zbierkach či fondoch osobitne spracovávajú knižnice, čo múzeá, galérie, archívy a iné typy PFI. Keď budujeme svoje digitálne knižnice, mali by sme dbať na to, aby stáli na dobrých základoch, ktoré umožnia jednoduchým spôsobom ich vzájomnú interoperabilitu. Kam smerujeme? Termín interoperabilita patrí medzi tie modernejšie, ale nadobúda čím ďalej, tým väčší význam. Interoperabilitu môžeme definovať ako schopnosť systémov, informačných a komunikačných technológií a pracovných procesov, ktoré tieto systémy podporujú, vzájomne si zdieľať a viacnásobne využívať údaje a znalosti.2 Aby neprišlo k zámene s kompatibilitou, navrhujeme doplniť túto definíciu o záver: „…online bez nutnosti ďalšej manipulácie s nimi“. Interoperabilita predstavuje problematiku, ktorá sa dotýka širokého spektra otázok zabezpečujúcich a umožňujúcich spoluprácu, zdieľanie a viacnásobné využívanie informačných zdrojov, od technickej cez organizačnú až po sémantickú3. Práve sémantická interoperabilita zohráva veľmi dôležitú úlohu. Cieľom interoperability je poskytovať používateľom kvalitné služby nad rôznymi distribuovanými heterogénnymi zdrojmi bez ohľadu na to, kto a akými prostriedkami tieto zdroje buduje a spravuje4. Vo svete i v Európe môžeme nájsť veľa úspešných projektov, kde sa podarilo interoperabilitu vyriešiť nielen na úrovni konkrétneho typu pamäťových inštitúcií, ale aj medzi pamäťovými inštitúciami či na medzinárodnej úrovni. Azda najznámejšie sú projekty DELOS, Europeana, ale tiež Tarchna či SCULPTEUR. Aj z týchto projektov je zrejmé, že sémantická interoperabilita stojí na dvoch základných pilieroch:
Systém organizácie poznania vychádza z definície organizácie poznania ako „popisu dokumentov, ich obsahu, vlastností a cieľov a organizácie takýchto popisov tak, aby bolo možné sprístupniť dokumenty a ich časti používateľom, ktorí vyhľadávajú alebo dokumenty samotné alebo informácie v nich obsiahnuté“5. Organizácia poznania zahŕňa všetky typy a metódy vecného a menného spracovania, klasifikácie, taktiež správu záznamov, bibliografiu a vytváranie databáz pre potreby informačného prieskumu. Na základe vymedzenia organizácie poznania potom systém organizácie poznania „zahŕňa všetky typy schém používaných v organizácii informácií a podporujúcich manažment znalostí“6. Za systémy organizácie poznania považujeme klasifikačné schémy, súbory autorít, tezaury a iné štruktúrované slovníky. O metadátových schémach sme už hovorili. Práve v týchto dvoch pilieroch sémantickej interoperability je rozdiel medzi našou krajinou a prostredím vyspelých západných krajín či anglicky hovoriacich krajín, kde systém organizácie poznania má svoju dlhoročnú históriu a dáta, ktoré sú evidované v informačných systémoch jednotlivých pamäťových inštitúcií, sa tvoria s ohľadom na zaužívané a centrálne spravované systémy organizácie poznania. U nás takéto systémy doteraz absentujú nielen na národnej úrovni, ale i na úrovni komunít či mnohých inštitúcií. Oveľa lepšie na tom nie sme ani s dodržiavaním štandardov v oblasti metadátových schém a pravidiel ich vypĺňania. Nedodržiavaním týchto štandardov a nedôslednou kontrolou pri tvorbe kultúrneho obsahu si len zhoršujeme svoju východiskovú pozíciu na zabezpečenie sémantickej interoperability. Systém organizácie poznania tvorí základ sémantickej interoperability len v súčinnosti s presne definovanými metadátovými schémami a pravidlami ich napĺňania. Niekto môže namietať, že v digitálnom svete máme možnosť podobnosť dokumentov riešiť na základe analýzy jazyka v kombinácii s využitím rôznych matematických metód a algoritmov, ako sú N-gramy, latentná sémantika, rôzne vzdialenostné metódy a podobne. Je to síce pravda, ale pomocou týchto, ale aj iných metód, asi len veľmi ťažko dosiahneme, aby stroj rozoznal, že Krym a Jalta v určitom kontexte patria k sebe, alebo keď hovoríme o liste, čo vlastne máme presne na mysli, teda v akom význame ho používame – či myslíme ten, čo píšeme priateľovi, alebo list zo stromu, či list-stranu z knihy a podobne. Kvôli tomu (okrem iného) zaviedli knihovníci a následne aj iné pamäťové inštitúcie do spracovania svojich fondov budovanie súborov autorít. Ak sa však pozrieme na definíciu, čo autority v knižniciach predstavujú, na to, ako sú budované (ako tieto záznamy vyzerajú a akú sémantiku obsahujú), a porovnáme to s tým, čo je definované vo funkčných požiadavkách na záznamy autorít, tak hneď na prvý pohľad vidíme značné rozdiely. Zásadný rozdiel je predovšetkým v miere štrukturalizácie údajov, a teda v tom, ako tie údaje do databázy zadávame. My síce napr. pri spracovaní osobnej autority v poznámke napíšeme, kedy presne (ak je nám to známe) a kde presne sa daná osoba narodila či zomrela, prípadne kde, kedy a čo študovala, ale tieto údaje sú zadávané vo forme, ktorá je síce strojom čitateľná, ale nie strojom spracovateľná. Práve preto si dovolíme tvrdiť, že v dostatočnej miere nereflektujeme na zmeny prostredia. Treba si uvedomiť, že dáta dnes nezapisujeme na katalogizačný lístok, ani si ich neukladáme do lokálneho počítača, ale umiestňujeme ich do prostredia webu, a preto by sme si mali uvedomiť aj to, ako web s údajmi pracuje a ako by sme ho mohli využiť pri spracovaní digitálneho obsahu. Dnes už totiž web neslúži len na sprístupnenie obsahu. Tvorcovia webu veľmi rýchlo prišli na to, že hoci web na jednej strane umožnil veľmi jednoduchý prístup k obsahu a prelinkovaniu dokumentov, tak na druhej strane nárast takýchto dokumentov vygeneroval ďalší problém, ktorý treba riešiť. Preto sa rozhodli pre web, ktorý neskôr dostal spoločné označenie web 2.0. Ten mal byť totiž pôvodne sémantickým webom, lenže z neho sa stal skôr web sociálny a zároveň nielen web na čítanie, ale ešte jednoduchšie publikovanie. Pre sémantický web sa teraz používa označenie web 3.0. Ak sa pozrieme na odborné články, ktoré sa zaoberajú sémantickým webom, tak je zrejmé, že jednou z hlavných súčastí sémantického webu sú ontológie. Opäť je to pojem, ktorý z pohľadu filozofie siaha veľmi ďaleko do histórie a predmetom jeho skúmania je tu bytie. V kontexte informatiky a informačných technológií však ontológia predstavuje a definuje množinu prvkov – pojmov, ich vlastností a vzťahov medzi týmto prvkami, pomocou ktorých je možné vytvoriť model určitej reálnej časti sveta. V našom kontexte môžeme hovoriť aj o modeli domény, konkrétne domény kultúrneho dedičstva. V literatúre sa uvádza viacero definícií, ale asi prvá a najznámejšia pochádza od T. Grubera, ktorý v roku 1992 definoval ontológiu ako „explicitnú špecifikáciu konceptualizácie“7. V roku 1997 túto definíciu doplnil Borst, keď ju rozšíril o dve slová. Tvrdí že ontológia predstavuje „formálnu explicitnú špecifikáciu zdieľanej konceptualizácie“8. Toto rozšírenie je prínosom, a to nielen z pohľadu spracovania údajov strojmi, kde je formalizmus potrebný, ale aj pre skutočnosť, že ontológia – a zvlášť doménová – je výsledkom konsenzu určitej záujmovej skupiny ľudí9. Pre kultúrne dedičstvo máme od roku 2006 k dispozícii doménovú ontológiu, ktorá bola prijatá aj ako ISO norma (ISO 21127), známa tiež aj ako CIDOC CRM, a ktorá bola vo februári 2008 vydaná aj ako STN ISO 21127 Informácie a dokumentácia. Referenčná ontológia na výmenu informácií kultúrneho dedičstva. CIDOC CRM je formálnou ontológiou, ktorej cieľom je poskytnúť sémantické definície a objasnenia potrebné pre transformovanie decentralizovaných a nesúrodých informačných zdrojov do jedného kompaktného zdroja. Toto je možné realizovať buď na úrovni inštitúcie, intranetu alebo internetu. CIDOC CRM prostredníctvom prostriedkov formálnej ontológie definuje podkladovú sémantiku databázových schém a štruktúry dokumentov, ktoré sa používajú pri spracovaní a dokumentácii kultúrneho dedičstva. Jej cieľom nie je určovať to, čo majú PFI robiť, ale skôr vysvetľuje logiku toho, čo v skutočnosti dokumentujú10, čím im umožňuje prepojenie kultúrneho obsahu na základe významu (sémantickú interoperabilitu), a to na konceptuálnej úrovni. Základný rozdiel medzi funkčnými požiadavkami, ktoré boli definované na úrovni knižníc, a ontologickým rámcom CIDOC CRM spočíva v prístupe, ako boli vytvárané, a tiež v tom, že CIDOC CRM pracuje s udalosťami, teda aj s entitami, ktoré sa môžu v čase meniť. Zatiaľ čo funkčné požiadavky boli spočiatku vytvárané ako entitno-relačný model, CIDOC CRM od počiatku uplatňuje objektový prístup. To bol, okrem iného, dôvod, prečo knihovníci pristúpili k harmonizácii FRBR so CIDOC CRM, a tak vznikol objektovo orientovaný model funkčných požiadaviek na bibliografické záznamy FRBROO. Keď sa bližšie pozrieme na to, čo všetko CIDOC CRM definuje, berieme do úvahy platné medzinárodné štandardy, pravidlá a odporúčania na spracovanie kultúrnych objektov v pamäťových inštitúciách, ktoré sme už stručne uviedli, a zároveň si uvedomíme, čo potrebujeme v súvislosti s digitálnymi knižnicami a ich sprístupnením a prepojením všetko riešiť, je zrejmé, že je najvyšší čas zmeniť paradigmy spracovania a využiť možnosti, ktoré nám dnešné informačné a komunikačné technológie ponúkajú. Vďaka technológiám sme dnes schopní spoločne tvoriť nielen záznamy, ale aj ich obsah, a to v heterogénnom prostredí a online. Keď sa pozrieme na to, aké údaje a znalosti pri spracovaní objektov kultúrneho dedičstva majú k dispozícii pracovníci jednotlivých PFI, tak vzájomnou spoluprácou sme schopní nielen na základe významu prepojiť obsahy informačných zdrojov, ktoré sú teraz budované oddelene, ale tiež vybudovať prostriedky a nástroje, ktoré by nám umožnili automatizované spracovanie digitálneho obsahu na základe významu. Ako na to? S prihliadnutím na to, čo sme uviedli, sa azda najjednoduchšou cestou javí pristupovať k spracovaniu na základe udalostí. Dôvod si vysvetlíme na jednoduchom príklade.
Ak sa pozrieme na záznam osobnej autority (napr. Josef Váchal) v súbore národných autorít ČR (obr. č. 1), tak vidíme, že strojom spracovateľné sú len údaje označujúce jeho meno a datáciu vymedzujúcu jeho život. V zázname máme ďalšie údaje, ktoré nám hovoria o jeho vzťahu k danému miestu a danej dobe. Ide o poznámku označenú ako biografické údaje. Toto sú údaje, ktoré knižnica pri spracovaní záznamu síce má k dispozícii, ale význam už zadáva spôsobom, ktorý je pre stroj len ťažko spracovateľný. Takýto záznam nevyhovuje napr. potrebám knižníc s regionálnymi funkciami, pretože ak ide o regionálnu osobnosť a chceme automatizovať zostavovanie kalendária, tak miera štrukturalizácie dát v takomto zázname nie je pre túto funkciu dostatočná.
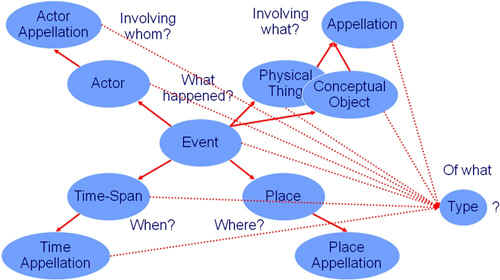
Z pohľadu CIDOC-CRM pre narodenie osoby identifikujeme nasledujúce triedy a ich vzťahy:
Ak sa bližšie pozrieme na CIDOC CRM a na to, čo v svojich systémoch dokumentujeme, tak môžeme povedať, že všetko, čo dokumentujeme, vzniká pri nejakej udalosti, ktorá sa deje za účasti nejakého aktéra a viaže sa na nejaké miesto a čas, pričom výsledkom udalosti je fyzický alebo umelý objekt. Zároveň sú všetky prvky určitého typu a všetko môžeme nejako identifikovať, označiť. Toto je znázornené na obr. č. 3.
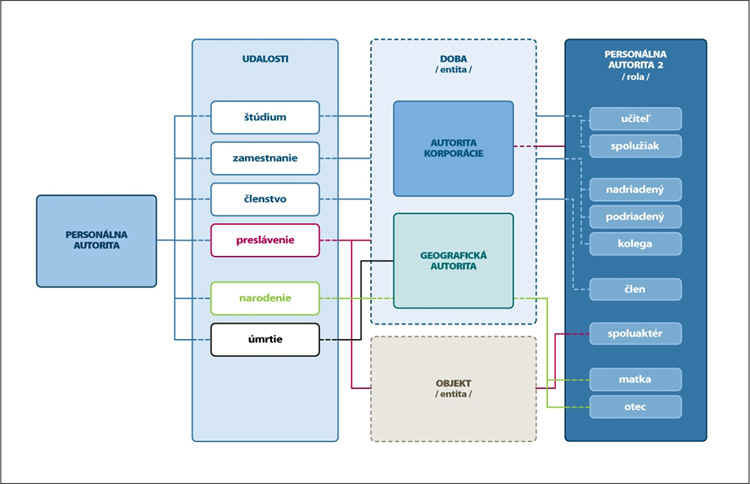
Obr. č. 3: Vzťahy medzi prvkami CIDOC CRM Prístup k spracovaniu na základe udalostí môžeme aplikovať rovnako na budovanie spoločného systému organizácie poznania, ktorý nevyhnutne potrebujeme na to, aby sme boli schopní dosiahnuť aspoň základnú úroveň sémantickej interoperability súčasných informačných zdrojov. Ak sa pozrieme napr. na osobné – personálne autority, tak z pohľadu požiadaviek knižníc, múzeí a archívov môžeme definovať viaceré udalosti, ktoré sú znázornené na obr. č. 4.
Samozrejme, tieto udalosti je možné postupne dopĺňať a podobne je možné spracovať návrhy aj pre ostatné entity či informačné objekty, ktoré tvoria základ popisu kultúrnych objektov spracovávaných v PFI. Takáto práca si vyžaduje samostatný výskum za účasti odborných pracovníkov zo všetkých typov PFI. Čo ďalej? Niet žiadnych pochýb, že ak sa chystáme budovať rozsiahle digitálne knižnice, kvalita ich sprístupnenia bude do značnej miery závisieť od popisných metadát. Preto ak chceme zabezpečiť prepojenie nezávisle budovaných digitálnych knižníc a následne aj prepojenie s digitálnym obsahom, ktorý v digitálnej podobe priamo vzniká, budeme musieť riešiť otázku sémantickej interoperability a následne aj otázku spracovania obrovského množstva digitálnych dokumentov. K úspešnému vyriešeniu obidvoch týchto úloh nám môže značne pomôcť práve nový prístup k spracovaniu, pričom ako prvé by bolo vhodné začať riešiť budovanie spoločného systému organizácie poznania, ktorého informačné objekty môžu vychádzať práve z jednotlivých typov záznamov autorít, ktoré bude nutné rozšíriť a obohatiť na úrovni obsahu aj rozsahu. Výhody, ktoré prístup k spracovaniu založený na udalostiach prináša, nám umožnia rozsah aj obsah jednotlivých záznamov budovať postupne, zároveň v oveľa väčšej miere spolupracovať, zdieľať a viacnásobne využívať zdroje aj informácie. Takto vybudovaný systém organizácie poznania bude zároveň tvoriť základ ontológie, ktorú budeme môcť následne využiť na automatizáciu spracovania digitálneho obsahu. Aj od nás bude závisieť to, ako rýchlo sa sémantický web rozšíri aj v praxi. Pokúsme sa akceptovať zmeny, ktoré nám prostredie prináša, a využívať technológie tak, ako nám to umožňujú, a nie ich brať len ako nevyhnutné zlo. Skúsme sa spoločne zamyslieť nad odpoveďami na niekoľko otázok:
Odpovede na tieto otázky prenecháme na vás, čitateľoch tohto článku.
Zoznam bibliografických odkazov ANDERSON, J. D. Organization of knowledge. In FEATHER, John – STURGES, Paul (ed.) International encyclopedia of information and library science. London, New York : Routledge, s. 336-353. ARMS, W. Y. Key Concepts in the Architecture of the Digital Library. In D-Lib [online]. July 1995 [cit. 2010-06-17]. BORST, W.N. Construction of Engineering Ontologies for Knowledge Sharing and Reuse. PhD dissertation, University of Twente, Enschede, 1997. GRUBER, Tom. What is an Ontology? [online]. [cit. 2010-06-17]. Dostupné na internete: <http://www-ksl.stanford.edu/kst/what-is-an-ontology.html>. HODGE, G. Systems of Knowledge Organization for Digital libraries : Beyond traditional authority files [online]. Washington : Council on Library and Information Resources [cit. 2010-06-17]. IDA. European interoperability framework for pan-european egovernmentservices : framework [online]. Version 4.2. January 2004 [cit. 2009-12-15]. LAGOZE, C. (ed.). Core Services in the Architecture of the National Digital Library for Science Education (NSDL) [online]. arXiv [cit. 2009-12-15]. LENHART, Zdeněk. CIDOC CRM – konečně řád do muzejní dokumentace? In Archviy, knihovny, muzea v digitálním světě 2005 [online]. [cit. 2010-06-21]. SVÁTEK, Vojtěch. Ontologie a WWW. In DATAKON 2002. Brno, 2002, s. 1–35. ISBN 80-210-2958-7. VODIČKOVÁ, Hana. Autorita. In KTD : Česká terminologická databáze knihovnictví a informační vědy (TDKIV) [online]. Praha : Národní knihovna České republiky, 2003 [cit. 2009-07-30].
2 VIDA. European interoperability framework for pan-european egovernmentservices : framework [online]. 3 LAGOZE, C. (ed.). Core Services in the Architecture of the National Digital Library for Science Education (NSDL) [online]. 4 ARMS, W. Y. Key Concepts in the Architecture of the Digital Library. 5 ANDERSON, J. D. Organization of knowledge. 6 HODGE, G. Systems of Knowledge Organization for Digital libraries : Beyond traditional authority files. 7 GRUBER, Tom. What is an Ontology? [online]. 8 BORST, W. N. Construction of Engineering Ontologies for Knowledge Sharing and Reuse. 9 SVÁTEK, Vojtěch. Ontologie a WWW. 10 LENHART, Zdeněk. CIDOC CRM – konečně řád do muzejní dokumentace? |